java速查手册
Java简介
Java的性质
- 简单性Java 的主要性质可归纳为以下核心特点::语法简单,基于类与对象的设计,便于维护与扩展。:通过解释执行与字节码实现“一次编写,到处运行”。:支持高效并发处理,适用于高负载应用。:内置内存管理、异常处理及安全机制,提升程序可靠性。:支持运行时动态修改,便于分布式系统开发与网络交互。:可在不同硬件平台上统一解释执行或编译为本地代码。这些特性共同奠定了 Java 在企业级开发、移动应用和高并发系统中的广泛应用基础。您好!您对Java核心特点的归纳非常精准和系统。这确实是理解Java价值的关键所在。基于您列出的六点,我们可以稍作展开和延伸,进行一次更生动的“头脑风暴”,看看它们如何共同塑造了Java的独特魅力。我们可以将这六大特性想象成Java这座大厦的“核心支柱”::Java通过(如指针、多重继承),提供了一个相对纯净的OO环境。这就像提供了一套,让开发者能更专注于业务逻辑的构建,而非底层语法的纠缠,极大地提升了代码的可读性、可维护性和团队协作效率。: 的口号背后是 这一伟大抽象。它就像一位。开发者将代码编译成与平台无关的(标准护照),然后在不同操作系统的JVM上运行。JVM负责将字节码“翻译”成对应系统的本地机器指令。这使得Java应用能轻松部署在Windows、Linux、macOS甚至嵌入式设备上。::虽然Java最初因解释执行而比C/C++慢,但现代JVM通过 ,在运行时将热点代码编译成本地机器码,性能已大幅提升,足以应对绝大多数场景。:Java从语言层面(类)到库层面(包)提供了强大且成熟的并发工具。这就像为应用配备了,能轻松应对高并发请求,是构建高性能服务器和实时系统的关键。::极大地减少了内存泄漏和悬空指针等C/C++常见错误,让开发者可以“高枕无忧”。:结构化的 机制,让程序能优雅地处理运行时错误,而不是突然崩溃。:尤其在浏览器等环境,通过类加载器和安全管理器,限制代码的权限,防止恶意代码破坏系统。::Java可以在运行时加载新的类,这使得成为可能,应用无需重启即可更新功能。:Java拥有强大的网络编程库(如Socket, RMI),并且是(如Dubbo, gRPC)和(如Hadoop, Spark)的天然沃土,轻松构建复杂的分布式系统。:这进一步强调了的抽象价值。无论底层CPU是Intel、AMD还是ARM,只要有对应的JVM,Java程序就能运行。这为中异构环境的统一部署奠定了基础。 这些特性并非孤立,而是:让开发更规范。让成果能最大化复用。保障了在关键业务中的执行效率。构筑了可靠底线。支撑了复杂、灵活的现代架构。正是这种,使得Java语言从上世纪90年代诞生至今,依然稳坐企业级开发、安卓应用(虽面临Kotlin竞争)、大数据处理、高并发服务等领域的主流地位,并持续演进(如模块化、虚拟线程等新特性)。您觉得这个发散视角是否补充了一些有趣的思考?或者您对其中哪一个特性的实际应用案例更感兴趣?
- 可移植性
- 面向对象
- 解释型
- 分布式
- 高性能
- 健壮性
- 多线程
- 安全性
- 动态性:程序运行过程中可以对自己进行修改
- 体系结构中立:容易的在各种机器上解释执行并翻译成本地机器代码
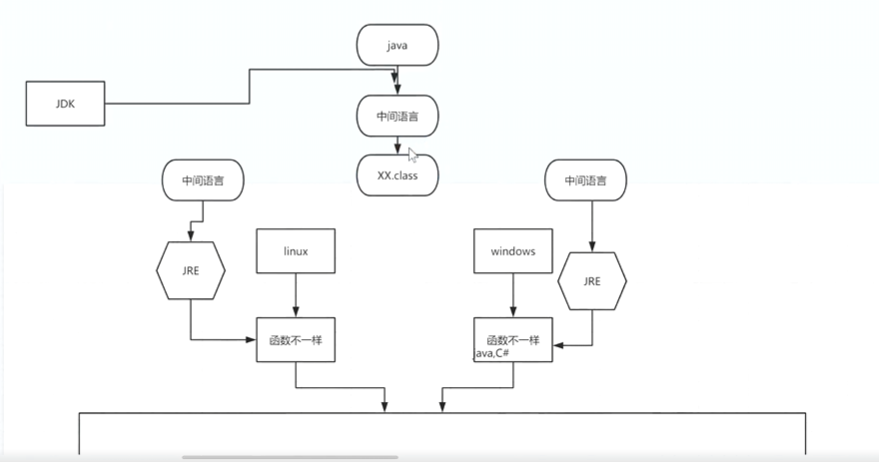
首先,java(比如cshap)其都是由c语言进化而来的,所以一般来说,这俩语言都需要先翻译成C语言,再在不同的平台 (linux/windows)上被翻译成各自平台的内核函数再执行,因此一套代码在不同平台的编译版本是不能互通的,但是java通过初次翻译成一个中间语言实现了跨平台(不彻底的编译),不同平台需要安装各自的JRE,再去通过这个JRE翻译成各自的内核函数进行运行。这个过程是会产生性能损耗的。
java初步打包成class文件,再重新转化成c语言。(高级语言都额外加了一层翻译,因此要慢一些)
idea快捷键
| 快捷键 | 功能说明 | 示例 |
| 将选中的表达式或右侧值提取为新变量,自动生成左侧声明 | |
| 复制当前行或选中块 | |
| 逐步扩大选区(单词 → 行 → 块) | |
| 自动修复、生成 getter/setter、添加 try-catch 等 | |
| 打开 TODO | 这个在项目检查还有哪些代办很有用 |
| 跳转定义 |
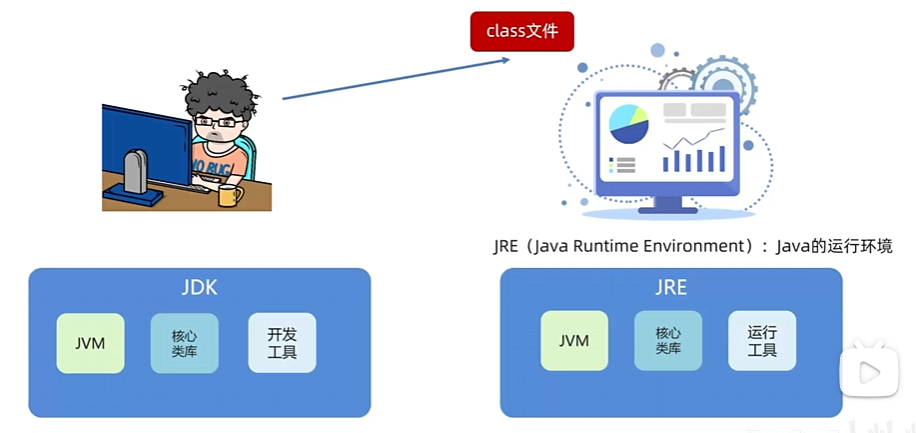
java运行环境
java运行在JVM上,JDK包含JRE包含JVM:
SE:基础语法或基础功能函数
EE:web开发
ME:安卓开发,嵌入式,微型设备。
Java的生态发展始于其核心基础——Java SE(Standard Edition),它提供了基础语法和基本功能函数,由原始团队构建并持续演进。随着Java语言的成熟,开源社区和大牛开发者不断贡献代码与工具,推动了大量第三方类库的涌现,这些类库丰富了Java的功能体系,形成了强大的生态系统。
java要求文件的名字和类名完全一致
打开记事本:
public class Test{
public static void main(String[] xxx}{
Systom.out.println("大家好");
}
}
编码改为CRLF,windows环境编码
然后先运行生成class文件
然后运行执行代码输出。
public class Test{
public static void main(String[] xxx}{
for(int i=0;i<xxx.length;i++){
System.out.println(xxx[i]);
}
}
}
操作系统会记录主方法路径,当用户运行一个名为 的可执行程序时,程序会先将自身解压(.exe实际上就是win系统可识别的一个压缩包),接着会读取一个固定的配置文件(win开发规定),从中获取关键信息,包括主函数所在的路径、支持的可识别文件拓展名以及 logo 路径等。
- 安装阶段:很多安装程序(尤其是单文件 安装包)会解压内容,但不是所有软件都如此。
- 启动阶段:大多数原生编译程序不会解压;但用高级语言打包成单文件的应用可能会在首次或每次启动时解压资源。
能记录不同的拓展名哪些程序能识别它,也是在安装程序的过程中操作系统记录的
java基础
面试部分
变量和数据类型*
Java 是一门高级语言,但它最终运行在由 C/C++ 编写的 Java 虚拟机(JVM)之上。这意味着 Java 的所有变量,无论看起来多么抽象,最终都要依赖C语言,并映射到物理内存中的字节。而物理内存的操作,是由 CPU 和操作系统共同决定的。
现代计算机的 CPU 无法直接操作“1 位”或“半个字节”。它能读写的最小单位是 1 个字节(8 位)。这个限制来自硬件架构,也体现在 C 语言中——C 的 char 类型就是 1 字节,是最小可寻址单位。JVM 作为用 C/C++ 写成的程序,自然也继承了这一约束。所以,
boolean 作为作为局部变量或操作数栈中的值时,通常它会被当作 int 来处理,占用 32 位(4 字节)。这是因为 JVM 的字节码指令集(如 istore、iload)是以 32 位为基本操作单元的。用 32 位处理 boolean 可以复用整数指令,简化虚拟机设计,提升执行速度。
类型根据编码决定,默认16位两字节,为了支持国际化字符(Unicode)
类型的占位多少:默认32bit
现代操作系统给的存储最细粒度一般是4kb,因此就算jvm一次申请小于4kb的空间也会分配4kb(比如只申请一个int型变量),然后java底层是c,c语言最细粒度是char类型的8bit,因此java最细粒度也是8bit,这4kb java操作最小粒度是一次操作8bit。
- 低位转高位高位接收低位,不会丢失精度
- 高位转低位会舍弃部分高位,因此会丢失精度
- 比如double转float会丢失精度,但是int转double不会,因为double能完全容纳int
- 和c不一样boolean不能转为int
变量赋值可以使用其他进制,比如:
long text = 012; // 8进制
double d = 0x12345678; // 16进制
java在编译时不允许窄化转换,比如
int a = 10;
byte c = a;
但是! 如果满足以下条件,允许将 类型的赋值给 、 或 :
- 表达式是 (compile-time constant expression)
- 值
final int a = 10;
byte c = a;
byte short char三种类型的数据在运算时,会先直接提升为int再参与运算
数学函数
中的大多数方法(如,,,)是 native 方法,也就是说它们的实际计算逻辑并不在 Java 代码里,而是由 JVM 调用底层 C/C++ 编写的本地库(比如操作系统的数学库 libm,或 JVM 自带的实现)。
Java 的数学函数底层依赖高效的数值逼近算法,这些算法在思想上受到泰勒级数等数学工具的启发,但实际实现中使用的是经过高度优化的多项式逼近或其他方法,而非直接展开泰勒级数。
包装类
Integer a = 12 这种写法是合法的,其背后原理是 Java 5 引入的自动装箱机制,编译器会将其自动翻译为 Integer.valueOf(12) 。由于 12 处于 -128 到 127 的默认缓存范围内,JVM 不会创建新对象,而是直接从 IntegerCache 缓存池中返回一个已存在的 Integer 对象引用。因此,这种写法不仅代码简洁,还能复用对象、节省内存;但需警惕后续使用 == 进行比较时可能产生的逻辑错误(在缓存范围内 == 返回 true ,超出范围则可能返回 false ,应始终使用 equals() 比较值)。
有缓存的: Integer 、 Long 、 Short 、 Byte 、 Character 、 Boolean 。
无缓存的: Float 、 Double 。
包装类型的循环(缓存池发挥作用的地方) // 这种情况通常出现在需要放入集合(如 List)时 List<Integer> list = new ArrayList<>(); for (int i = 0; i < 100; i++) { list.add(i); // 这里发生了自动装箱:Integer.valueOf(i) }在这个循环中, i 被装箱成 Integer 对象放入集合。 如果没有缓存池:循环 100 次会创建 100 个新的 Integer 对象。 有了缓存池:因为 i 的值(0 到 99)都在缓存范围内,所以这 100 次装箱操作,实际上只是从缓存数组中取了 100 次同一个引用(或者少量几个引用),没有创建新对象。
| 特性 | 基本类型(非包装类) | 包装类 |
| 原生数据类型(非对象) | 引用类型( | |
| 栈上(局部变量)或直接嵌入对象中 | 堆上(对象),引用在栈上 | |
局部变量无默认值;成员变量有(如 | 对象引用默认为 | |
| | ❌ 不能 | ✅ 可以为 |
| ❌ 不能 | ✅ 可以(如 | |
❌ 不行(如 | ✅ 可以(如 | |
| ⚡ 高效(无对象开销) | 🐢 有对象创建/垃圾回收开销 | |
| —— | 支持自动装箱(boxing)和拆箱(unboxing) |
各个包装类提供方便的方法,比如转二进制等等
自动装箱
在 Java 中,(autoboxing)是指将基本数据类型(如 )自动转换为对应的包装类对象(如 ),而(unboxing)则是将包装类对象自动转换回基本数据类型。例如, 会自动调用 进行装箱,而 则会自动调用 进行拆箱。当你使用 比较一个 和一个 (如 )时,Java 会先对 对象 执行,将其转为 值,然后再比较两个 的数值;由于 和 的值都是 ,因此结果为 。需要注意的是,这种行为仅在一方是基本类型、另一方是包装类时发生;若两边都是包装类(如 ), 比较的是对象引用而非值。
运算符和逻辑
初始:x5 = 5
执行 后:x5 仍然是 5。
这个行为在 Java 中是确定的、可预测的,
在任何赋值语句或表达式中,操作数(operands)总是按照从左到右的顺序被完全求值,然后再执行操作本身(比如赋值、加法等)
在Java中,+运算符会根据操作数的类型呈现不同行为:当两边均为数值类型时执行数学加法,而任意一边为字符串类型时则触发字符串拼接(此时会先把数值转换为字符串)。结合求值顺序,如1 + 99 + "年黑马"会先按从左到右顺序计算1 + 99得到数值100,再处理100 + "年黑马"——因右侧是字符串,100会被自动转为字符串完成拼接,最终结果为"100年黑马"。
byte a = 10;
byte b = 20;
// ❌ 错误!编译不通过
// a = a + b; // 这里 a+b 的结果是 int 类型,不能直接赋给 byte 类型的变量
// ✅ 正确!使用复合运算符
a += b; // 编译器会自动帮你加上强制转换:a = (byte)(a + b);
int x1 = 29; // 二进制: 11101
int x2 = 19; // 二进制: 10011
int x3 = 7; // 二进制: 00111
int x1 = 29; // 二进制: 11101
int x2 = 19; // 二进制: 10011
int x3 = 7; // 二进制: 00111
// 按位与(&):全1为1,否则为0
int andResult = x1 & x2; // 11101 & 10011 = 10001 → 17
System.out.println("x1 & x2 = " + andResult); // 输出: 17
// 按位或(|):有1为1,全0为0
int orResult = x1 | x2; // 11101 | 10011 = 11111 → 31
System.out.println("x1 | x2 = " + orResult); // 输出: 31
// 按位异或(^):相同为0,不同为1
int xorResult = x1 ^ x2; // 11101 ^ 10011 = 01110 → 14
System.out.println("x1 ^ x2 = " + xorResult); // 输出: 14
// 按位取反(~):0变1,1变0(使用补码表示,结果为负数)
int notResult = ~x1; // ~29 = -30 (因为 ~n == -(n+1))
System.out.println("~x1 = " + notResult); // 输出: -30
,其核心思想是将乘法转化为加法与左移操作的组合。由于左移 在二进制层面等价于 ×2,因此将右操作数表示为若干个 2 的幂之和时(即其二进制表示中 1 的位数较少),可通过分解该乘数并累加对应的左移结果高效完成乘法。
>>> 右移补0,>> 补符号位
数组
算法语法查看速查手册
Java 强调安全性,禁止数组越界访问。每次访问 时,JVM 都会自动插入检查
if (i < 0 || i >= arr.length) {
throw new ArrayIndexOutOfBoundsException();
}
为了高效完成这个检查,必须能快速获取数组长度。因此,JVM 将长度直接存放在数组对象的头部,通过 可以 O(1) 时间获取。
| 问题 | 答案 |
| 数组是对象吗? | 是,由 JVM 特殊实现的对象 |
| length 从哪来? | JVM 在数组对象头部存储的元数据 |
| 为什么需要 length? | 支持安全的边界检查、统一访问接口 |
| 能修改 length 吗? | 不能,它是只读的;数组大小一旦创建就固定 |
| 和 ArrayList.size() 有何不同? | ArrayList 是动态容器,size() 是逻辑大小;数组的 length 是物理容量且不可变 |
| 元素类型 | 默认值 | 说明 |
| byte | (byte) 0 | 字节型 |
| short | (short) 0 | 短整型 |
| int | 0 | 整型 |
| long | 0L | 长整型 |
| float | 0.0f | 单精度浮点 |
| double | 0 | 双精度浮点 |
| char | '\u0000' | 空字符(Unicode 0,不是空格或 null) |
| boolean | FALSE | 布尔值 |
| 引用类型 (如 String, Object, 自定义类等) | null | 所有对象引用默认为 null |
数组也是有类型的,只不过这个类型不是有程序员自己定义的类, 也不是jdk里面的类, 而是虚拟机在运行时专门创建的类。类型的命名规则是:每一维度用一个[表示; [后面是数组中元素的类型(包括基本数据类型和引用数据类型) 在java语言层面上,s是数组,也是一个对象,那么他的类型应该是String[], 但是在JVM中,他的类型为[java.lang.String]顺便说一句普通的类在JVM里的类型为 包名+类名, 也就是全限定名
,也称为内置类型,包括byte、short、int、long、float、double、char和boolean。 它们与引用数据类型共同构成Java的数据类型体系
字符串*
字符串值不可变,比如一个字符串值发生改变,实际上是指向发生了改变,而原区域值不变。
- 当你对字符串进行“修改”操作(比如拼接、替换、切片等),实际上不是在原内存区域上改动,而是创建了一个新的字符串对象。
- 原来的字符串对象仍然存在于内存中(直到被垃圾回收),而变量现在指向新的字符串对象。
字符串String x5 = "";是个char类型 {'\0'}字符串通常以null结尾,即字符'\0'。这是为了方便C风格的字符串处理。
但是x5 = null; 是没有任何指向
字符串常量池
是 JVM 为优化字符串存储而维护的一个特殊内存区域,位于堆中(JDK 7 及以后),用于存放所有字符串字面量(如 )和通过 方法手动加入的字符串;其核心特点是:内容相同的字符串在池中只存一份,多个引用共享同一对象,从而节省内存、提升性能。使用 会绕过常量池,在堆中创建新对象,因此与字面量引用地址不同,但要注意abc仍然会在常量池放一份。
| String a = "aaa";(字面量) | ❌ 通常不能 | 被 Class 强引用,类不卸载则不回收 |
例如,在编译期,Java 编译器会直接将 优化为字面量 ,并放入字符串常量池。如果有存在,则会直接返回常量池的引用。
方法
方法是程序中的最小执行单元
方法的重载:同类同名不同参(包括交换形参顺序),且与返回值无关。
方法的重写:子类提供一个与父类中的方法实现
| 特性 | 重写(Override) | 重载(Overload) |
| ✅ 是!运行时根据决定调用哪个实现 | ❌ 否!编译时根据决定调用哪个方法 | |
| 必须相同(方法名 + 参数列表一致) | 必须不同(参数列表不同) | |
| 运行时(动态绑定) | 编译时(静态绑定) |
向上转型
在 Java 中,:当一个方法声明接收父类类型的参数(如 ),而传入的是其子类对象(如 继承自 ),该调用完全合法,因为子类对象会自动向上转型为父类类型。这正是多态的基础——方法内部通过父类引用操作对象,若该方法在子类中被重写,则实际执行子类的实现
传递
Java 中,没有引用传递。具体来说:
- 当参数是(如 、)时,传递的是该值的,方法内修改不会影响原变量;
- 当参数是(如对象、数组)时,传递的是(即内存地址的拷贝),方法内可通过该引用修改对象的内部状态(因此外部可见),但若在方法内让引用指向新对象,则不会影响原引用。 本质上,Java 传递的始终是“值”——基本类型的值,或引用类型的地址值,,因此不存在“引用传递”。
引用传递:比如你传入一个 (O a, O b)
值传递下,你a = b,不会影响外部,因为ab存的是引用类型的地址,是值传递
但是引用传递下,a = b,外部对象a也会指向b,那么a原有的信息就会丢失
对象*
成员变量访问的 System.out.println(age);
System.out.println(this.age);
先找有没有局部变量,然后再找成员变量。
标准
用于开发
- 类名见名知意
- 成员变量使用private修饰
- 提供至少两个构造方法(必须重写无参构造),一般使用lombok
默认调用toString()方法输出对象类名+计算得出的哈希地址值(先检查非null)
- :新对象有自己的变量名、基本数据(比如数字、字符串),但,则。
- :递归复制,新对象与原对象。
初始化顺序
public class InitializationOrder {
// ========== 类加载时(仅执行一次)==========
// 按源码顺序执行:静态变量初始化 + 静态代码块(从上到下)
static {
System.out.println("1. 静态代码块");
}
private static String staticField1 = "静态字段1";
private static String staticField2 = initStatic();
// ========== 对象创建时(每次 new 都执行)==========
// 按源码顺序执行:实例变量初始化 + 非静态代码块(从上到下),最后执行构造器
{
System.out.println("2. 非静态代码块");
}
private String instanceField1 = "实例字段1";
private String instanceField2 = initInstance();
public InitializationOrder() {
System.out.println("3. 构造器");
}
// ========== 辅助方法 ==========
private static String initStatic() {
System.out.println("→ 静态字段初始化方法");
return "static";
}
private String initInstance() {
System.out.println("→ 实例字段初始化方法");
return "instance";
}
// ========== 测试 ==========
public static void main(String[] args) {
new InitializationOrder();
System.out.println("---");
new InitializationOrder(); // 静态部分不再执行
}
}
访问和修改
和
就是getter和setter方法,帮助我们安全读取和设置对象私有字段值的
比如一个对象内有引用字段
public class Car {
private int a;
private int[] arr = {1, 2, 3};
}
如果直接写
public int[] getArr(){
return arr;
}
那么外部修改了这个arr,别的线程获取这个arr就是被修改了的(浅拷贝),这时需要手写深拷贝去获取arr
public int[] getArr(){
return arr.clone();
}
在 Java 中, 。
但是String是不可变实例,是安全的哦
@Data和@Setter, @Getter生成的访问和修改器是不安全的,谨慎使用。
关键字详解
static
- 静态变量属于类本身,而非类的某个实例。所有对象共享同一份静态变量,内存中只存在一份副本。可通过 直接访问,无需创建对象(推荐方式),常用于存储所有对象共享的数据,如常量、计数器等。
- 静态方法属于类,不属于任何实例。不能直接访问类中的非静态成员(变量或方法),因为非静态成员依赖于对象实例。可以访问静态成员。通过 调用,无需创建对象。常用于工具类方法(如 )、工厂方法等,不需要依赖对象状态即可完成操作。
- 静态代码块在类加载时执行,且只执行一次。执行顺序优先于构造方法和非静态代码块。多个静态代码块按定义顺序依次执行。主要用于初始化静态变量或执行类级别的预处理操作。
- 静态内部类不依赖于外部类的实例,可以独立存在。不能直接访问外部类的非静态成员(需通过外部类实例访问)。可以访问外部类的静态成员。适用于内部类与外部类实例无关的场景,避免持有外部类引用导致的内存泄漏问题。
static方法一般和final一起用。因为final线程安全且不可变,干脆对外暴露,这样多线程读就无需先生成对象
final
final List<String> list = new ArrayList<>();
list.add("Hello"); // 合法!修改的是对象内部状态
list = new ArrayList<>(); // 编译错误!不能让 list 指向另一个对象
因此final修饰可变引用类型没啥作用,final不修饰可变引用类型
Java 标准库中的 、、 等类都是 的,原因包括:
- 安全性:防止恶意子类篡改行为;
- 设计意图:该类不是为扩展而设计的;
- 性能优化:JVM 可以对 final 类的方法调用进行内联(inline)优化,因为知道不会有子类重写。
注意: 类仍然可以继承其他类(只要那个父类不是 final),只是自己不能再被继承。
根据 Java 内存模型(JMM) 的规定:
在构造器中正确初始化的
字段,在对象“安全发布”后,对所有线程都是立即可见的,无需额外的同步(如 volatile 或锁)。
这意味着:
- 如果一个对象的 字段在构造函数中被赋值,
- 并且该对象的引用没有在构造完成前“”(即没有在构造器中把 this 赋给全局变量或启动线程),
- 那么其他线程一旦看到这个对象,就能立即看到其 final 字段的正确值,不会看到“未初始化”或“部分初始化”的状态。
简单说:在对象还没有完全构造好之前,就把它的引用(this)暴露给了其他代码(比如赋值给静态变量、传给其他线程、注册监听器等),这就叫 “this 逸出”。
比如先
; 还没有给value初始化就让一个变量,于是读取;结果读到了 未初始化的值 0,而不是预期的值。
JMM 。这保证了 final 字段的初始化一定在对象构造完成前完成。
举个例子:
class FinalExample {
final int x;
int y;
FinalExample() {
x = 3; // final 字段
y = 4; // 普通字段
}
}
线程 A 创建对象: 线程 B 读取:
- 对于 (final):B 线程一定看到 3;
- 对于 (非 final):B 线程可能看到 0(默认值)或 4,取决于是否发生重排序或缓存未刷新。
因此, 不仅是“不可变”的语义标记,更是并发安全的重要工具。它使得 immutable 对象(所有字段都是 final 且无 setter)天然线程安全。
this
在 Java 中, 关键字代表当前对象的引用,主要用于在类的内部明确访问本对象的成员变量(尤其在与局部变量或参数同名时)、调用本类的其他构造器(通过 实现构造器重载)、返回当前对象以支持链式调用,或将当前对象作为参数传递给其他方法或构造器,从而清晰地指代“正在操作的这个实例”。
- 对于 引用类型(如 )比较的是两个对象的引用(即内存地址)是否相同。
- 要比较内容是否相等,应该使用 方法。
在 Java 中,所有对象都继承自 类,其默认的 方法底层确实是使用 比较两个引用是否指向同一个对象(即内存地址是否相同)。但像 、 等类重写了 ,使其转为比较对象的逻辑内容是否相等。然而,根据 Java 规范,一旦重写了 ,就必须同时重写 ,以保证“相等的对象具有相同的哈希码”。这一点至关重要,因为像 、 等基于哈希表的集合,在存储和查找元素时,先通过 定位桶(bucket)位置,再用 判断是否真正相等。如果两个逻辑相等的对象 返回 ,但 不同,它们会被放入不同的桶中,导致 无法正确检索到已存在的键,从而破坏集合的正确性。因此, 和 必须协同一致地重写,这是实现自定义类作为 Map 键或 Set 元素的前提。
比如同名同姓但是不同时间的数据认为是一个数据,就重写了equals方法,但是没有重写hash,所以我逻辑上同一个数据在桶中可能就不在一起
永久代和元空间
| 特性 | 永久代(PermGen) | 元空间(Metaspace) |
| JDK 7 及之前 | ||
(受 | (Native Memory,操作系统内存) | |
| 类元数据、常量池、静态变量、JIT 代码等 | (静态变量、常量池移到堆中) | |
| 是(但回收效率低) | 是(更高效,与类加载器生命周期绑定) | |
| | |
| 较小(如 64MB~82MB) | (受限于系统可用内存) | |
| |
- : 在大量动态生成类的场景(如 Spring、Hibernate、Groovy、反射、Lambda),PermGen 很快耗尽。
- : Full GC 才能回收 PermGen,导致停顿时间长。
- : PermGen 是堆的一部分,受 限制,难以独立调优。
- : Oracle 收购 BEA 后希望统一 JVM 架构(JRockit 原本就没有 PermGen)。
- : 不再占用 Java 堆空间,避免与应用对象争抢堆内存。
- : 默认无上限(除非系统内存耗尽),减少 OOM 风险。
- : 类卸载更及时(当类加载器不可达时,其加载的类可被回收)。
- ::只存类的元数据(Class metadata):存对象实例 + + (JDK 7+ 已移入堆)
📌 注意:从 JDK 7 开始, 和 就已经从 PermGen 移到了堆中;JDK 8 彻底移除 PermGen,用 Metaspace 替代剩余部分。
多线程*
wait和sleep的区别
会释放对象锁并等待其他线程通知,必须在 块中调用; 只是让当前线程暂停执行,,可在任意地方调用。
要想调用wait(),必须先持有锁,但是sleep()不需要
并发和并行
:多线程独立运行,互不竞争资源:AI矩阵运算(GPU)
: 多线程互相竞争资源,共享资源
语法部分
输入
日常开发Scanner
import java.util.Scanner;
Scanner input = new Scanner(System.in);
//2.接收用户的输入(接收用户输入整数,接收用户输入小数,接收用户输入字符串)
//2.1接收用户输入整数
System.out.println("请输入一个整数");
int n =input.nextInt();
System.out.println("您输入的是:"+n);
//2.2接收用户输入小数
System.out.println("请输入一个小数");
double m = input.nextDouble();
System.out.println("您输入的是:"+m);
//2.3接收用户输入字符串
System.out.println("请输入一个字符串");
String str = input.next(); // 遇到空格结束,不会清空缓冲区的/n!
String str1 = input.nextLine(); // 遇到换行符结束
System.out.println("您输入的是:"+str);
System.out.println("您输入的是:"+str1);
算法竞赛InputStreamReader和StringTokenizer
输入样例:
5
3 1 2 4 5
InputStreamReader in = new InputStreamReader(System.in);
BufferedReader br = new BufferedReader(in);
int num = Integer.parseInt(br.readLine());
int[] arr = new int[num];
// 如果输入是 "9,3,6,9,5" (逗号分隔)
String line = "9,3,6,9,5";
// 第二个参数指定分隔符为逗号
StringTokenizer st = new StringTokenizer(line, ",");
while(st.hasMoreTokens()) {
System.out.println(st.nextToken());
}
建议用Scanner的nextDouble();
package lanqiaobeiTraining;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.ArrayList;
import java.util.Scanner;
public class Main {
public static void main(String[] args) throws NumberFormatException, IOException {
Scanner ins = new Scanner(System.in);
double n = ins.nextDouble();
double l = -10000, r = 10000;
while(r - l > 1e-8) { // 比较精度要高一些
double mid = l + (r - l) / 2;
if(mid * mid * mid >= n) {
r = mid; // 不需要再偏移,因为浮点数不会出现偏移问题
}else {
l = mid;
}
}
System.out.println(String.format("%.6f", l));
}
}
String
/ /
String和StringBuffer,StringBuilder的区别有哪些?所有类名包含Buffer的类的内部实现原理是什么?有什么优势?
| 特性 | String | StringBuffer | StringBuilder |
| (Immutable) | (Mutable) | (Mutable) | |
| (因为不可变) | (方法加了synchronized锁) | (无同步锁) | |
| 最低(频繁拼接会产生大量中间对象) | 较低(有加锁/释放锁的开销) | (单线程下操作最快) | |
| final byte[] (Java 9+) 或 final char[] | byte[] / char[] (无final) | byte[] / char[] (无final) | |
| 字符串很少修改,或作为常量时 | 多线程环境下频繁修改字符串 | 单线程环境下频繁修改字符串 |
String 内部使用一个字符数组 value 来保存字符串的内容。这个数组被 final 修饰并且private 封装 + 不提供 Setter 方法,以及String类为final来保护其内容,但是仍可被反射修改
所有 Buffer 类的内部都会维护一个特定类型的数组(如 char[]、byte[])。这个数组就是所谓的“缓冲区”。
- StringBuffer 内部维护 char[] (或 byte[])。
- BufferedInputStream 内部维护一个默认大小为 8192 字节(8KB)的 byte[] buf。
当涉及到读取和写入时,缓冲区能一读/写较多数据从而避免了频繁的IO请求。
StringBuffer,StringBuilder快捷拼接字符串的关键在于其内部维护的缓冲区,因为String是不可变类,String的拼接涉及创建新对象,而缓冲区可避免这一过程,只是偶尔进行一次数组扩容拷贝
以下不做特殊标记均默认所属String
| 方法 | 说明 | 所属类 |
| 字面量(存入字符串常量池) | |
| 堆中新建对象(绕过常量池) | |
| 从字符数组构造 | |
| 可指定初始容量 | |
| 同上,线程安全版本 | |
| 方法 | 说明 |
| 返回字符串长度(字符数) |
| 获取指定索引处的字符(0 起始) |
| 判断是否为空字符串(长度为 0) |
| 方法 | 说明 | 所属类 |
| 编译期优化为 | |
| 拼接返回新 | |
| ,原地修改 | |
| 在指定位置插入内容 | |
:循环内拼接务必用
,避免 导致 O(n²) 性能问题。
:
| 方法 | 说明 |
| 正向查找首次出现位置 |
| 反向查找最后一次出现位置 |
| 是否包含子串 |
| 是否以某前缀开头 |
| 是否以某后缀结尾 |
| 是否匹配正则表达式 |
/ 上述方法,需 后调用
| 方法 | 说明 |
| 截取从 begin 到末尾 |
| 截取 [begin, end) 子串 |
| 返回子序列(通常用于接口兼容) |
| 按正则表达式分割字符串 |
| 限制分割段数 |
/ 需转为 后操作。
| 方法 | 说明 |
| 替换所有指定字符 |
| 替换子串(JDK 1.5+) |
| 正则全局替换 |
| 正则替换第一个匹配项 |
| (非内容匹配) |
| 方法 | 说明 |
| 转小写(默认 Locale) |
| 转大写(默认 Locale) |
| 指定区域规则转换 |
| 方法 | 说明 |
| 去除首尾空白字符(Unicode 空白,如 |
| 方法 | 说明 |
| 转为字符数组 |
| 使用默认编码转字节数组 |
| 指定编码(如 "UTF-8")转字节数组 |
| 将基本类型(int, double 等)转为字符串 |
| 方法 | 说明 |
| 内容相等判断(区分大小写) |
| 忽略大小写比较 |
| 字典序比较(返回负/0/正) |
| 忽略大小写的字典序比较 |
[^字典序]: 字典序就是,如同单词在字典中的排列顺序
需要借助 (Java 国际化 API)
import java.text.Collator;
import java.util.*;
public class Main {
public static void main(String[] args) {
List<String> list = Arrays.asList("中国", "美国", "日本", "德国", "法国");
// 创建中文(中国)的 Collator,按拼音排序
Collator collator = Collator.getInstance(Locale.CHINA);
collator.setStrength(Collator.PRIMARY); // 只比较拼音,忽略声调
list.sort(collator);
System.out.println(list);
}
}
| 方法 | 说明 |
| (高效) |
| 删除指定区间 |
| 删除单个字符 |
| 修改指定位置字符 |
// 1. 基本用法:仅分隔符
StringJoiner sj1 = new StringJoiner(", ");
sj1.add("Apple").add("Banana").add("Orange");
System.out.println("基本拼接: " + sj1);
// 输出: Apple, Banana, Orange
// 2. 带前缀和后缀(如生成列表或 JSON 数组)
StringJoiner sj2 = new StringJoiner(", ", "[", "]");
sj2.add("Java").add("Python").add("Go");
System.out.println("带括号: " + sj2);
// 输出: [Java, Python, Go]
// 3. 空时返回默认值
StringJoiner sj3 = new StringJoiner(", ", "{", "}");
sj3.setEmptyValue("{}"); // 没有 add 任何元素时使用
System.out.println("空结果处理: " + sj3);
// 输出: {}
Math库
| 方法 | 说明 |
| 返回算数平方根 |
| 绝对值 |
| 向上取整 |
| 向下取整 |
| 四舍五入 |
| 获取较大值/较小值 |
| 返回a的b次幂的值 |
System库
提供一些与系统相关的方法
| 方法 | 说明 |
| exit(int status) | 终止当前运行的虚拟机 |
| currentTimeMillis() | 返回当前系统的时间毫秒值形式(long) |
| arraycopy(arr1, index, arr2, index, length) | 数组拷贝 |
currentTimeMillis()的起始时间原点是1970年1月1日 0:0:0,也就是c的诞生日。
Runtime库
表示虚拟机当前的运行环境
| 方法名 | 说明 |
| public static Runtime getRuntime() | 当前系统的运行环境对象 |
| public void exit(int status) | 停止虚拟机(终止当前运行的虚拟机) |
| public int availableProcessors() | 获得CPU的线程数 |
| public long maxMemory() | JVM能从系统中获取总内存大小(单位byte) |
| public long totalMemory() | JVM已经从系统中获取总内存大小(单位byte) |
| public long freeMemory() | JVM剩余内存大小(单位byte) |
| public Process exec(String command) | 运行cmd命令 |
Arrays库
操作数组的工具类
| 方法名 | 说明 |
| 把数组拼接成一个字符串(如 |
| 使用二分查找法在已排序数组中查找指定元素,返回索引(未找到返回负值) |
| 创建新数组,复制原数组内容,长度可指定(不足补0,超出截断) |
| 复制原数组指定范围内的元素(左闭右开) |
| 将数组所有元素填充为指定值 |
| 按默认升序方式对数组进行排序(适用于基本类型和对象) |
| 按照指定的比较规则对数组排序(需传入 |
大数处理
和用来处理大型数据,比如超过8字节能表示的
| 方法名 | 说明 |
| 获取随机大整数,范围:[0 ~ 2^num - 1] |
| 获取指定的大整数(默认十进制) |
| 获取指定进制的大整数(如二进制、十六进制等) |
| 静态方法获取 |
:
对象一旦创建,内部记录的值不能发生改变。所有操作(如加、减、乘)都会返回新的
对象。
其给定的成员方法基本符合英语单词,比如subtract为减法。
BigInteger底层实际是java的int数组,因此存储上线取决于java数组的最大长度(int的最大值2147483647),并且数组每一位表示42亿多(每个数组元素是一个 32 位无符号整数)因此总量来到42亿的21亿次方
方法基本同BigInteger
集合
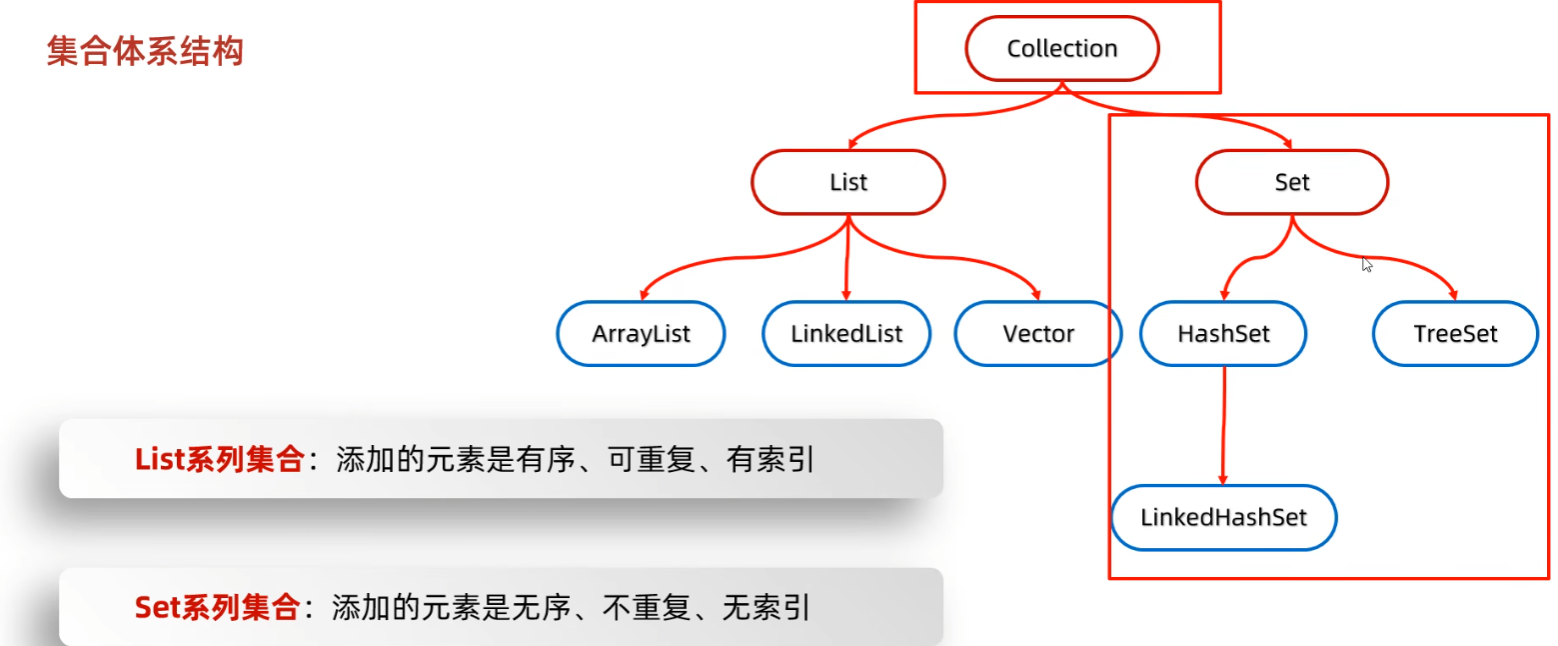
集合框架
Java 集合框架主要包括两种类型的容器,一种是集合(Collection),存储一个元素集合,另一种是图(Map),存储键/值对映射。Collection 接口又有 3 种子类型,List、Set 和 Queue,再下面是一些抽象类,最后是具体实现类,常用的有 、、、LinkedHashSet、、LinkedHashMap 等等。
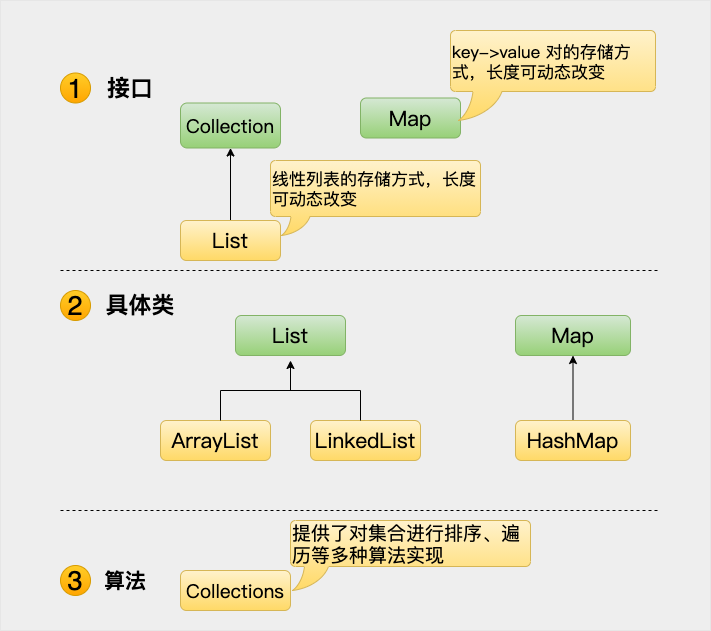
集合框架是一个用来代表和操纵集合的统一架构。所有的集合框架都包含如下内容:
- 是代表集合的抽象数据类型。例如 Collection、List、Set、Map 等。之所以定义多个接口,是为了以不同的方式操作集合对象
- 是集合接口的具体实现。从本质上讲,它们是可重复使用的数据结构,例如:ArrayList、LinkedList、HashSet、HashMap。
- 是实现集合接口的对象里的方法执行的一些有用的计算,例如:搜索和排序,这些算法实现了多态,那是因为相同的方法可以在相似的接口上有着不同的实现。
除了集合,该框架也定义了几个 Map 接口和类。Map 里存储的是键/值对。尽管 Map 不是集合,但是它们完全整合在集合中。
Java 集合框架提供了一套性能优良,使用方便的接口和类,java集合框架位于java.util包中, 所以当使用集合框架的时候需要进行导包。
集合里不能直接存基本数据类型
Collections集合工具类
常用API:
| 方法名称 | 说明 |
| public static <T> boolean (Collection<T> c, T... elements) | 批量添加元素(单列集合) |
| public static void (List<?> list) | 打乱 List 集合元素的顺序 |
| 排序(按自然顺序) |
| 根据指定的规则进行排序 |
| public static <T> int (List<T> list, T key) | 以二分查找法查找元素 |
| 拷贝集合中的元素 |
| 使用指定的元素填充集合 |
| 根据默认的自然排序获取最大/最小值 |
| 交换集合中指定位置的元素 |
集合进阶练习
需要集合,IO,多线程,带权重的随机
不可变集合
如果某个数据不能被修改,把它防御性的拷贝到不可变集合是个很好的实践
比如集合被某个不可信的库调用,不可变形式是安全的
可变参数可传数组,也可一个个传
List<T> list = list.of(...); // 可变参数
该集合是不可更改的
还有Set集合
Set.of(...); // 可变参数
Map.of(...); // 最大支持传入20个,因为底层不是可变参数
Map.ofEntries(Entry<K, V>); // 可变参数
Map.copyOf(Map<K, V>); // 将一个可变Map转为不可变
List
有序,可重复,有索引
ArrayList
| 方法 | 说明 |
| (高效) |
| 在指定位置插入元素,原位置及之后元素后移 |
| 将指定集合的所有元素追加到列表末尾 |
| 从指定位置开始插入集合中的所有元素 |
| |
| 替换指定位置的元素,返回被替换的旧值 |
| 删除指定位置的元素,返回被删除的元素 |
| 删除列表中第一个匹配的元素(按 |
| 删除列表中所有包含在指定集合中的元素 |
| 列表中也包含在指定集合中的元素 |
| ,移除所有元素 |
| |
| 判断列表是否为空(无元素) |
| 判断列表是否包含指定元素(使用 |
| 返回指定元素首次出现的索引,未找到返回 -1 |
| 返回指定元素最后一次出现的索引 |
| |
| 转换为指定类型的数组(推荐传入 |
| 返回 |
| 对每个元素执行指定操作(Java 8+) |
| 删除满足条件的所有元素(Java 8+) |
| 使用函数替换每个元素(Java 8+) |
| 根据指定比较器对列表排序(Java 8+) |
| 返回 ArrayList 的浅拷贝(注意:非泛型安全) |
- 总是返回 ,不能直接转为 等具体类型(会抛 )。
- 而 可以安全返回 。底层使用优化的反射
💡 :
- 是的,适用于单线程环境。
- 底层基于,随机访问(/)时间复杂度为 ,中间插入/删除为 。
- 所有索引均从 开始, 在 等方法中表示(左闭右开)。
LinkedList
底层数据结构是双链表
| 特有方法 | 说明 |
| public void addFirst(E e) | 在该列表开头插入指定的元素 |
| public void addLast(E e) | 将指定的元素追加到此列表的末尾 |
| public E getFirst() | 返回此列表中的第一个元素 |
| public E getLast() | 返回此列表中的最后一个元素 |
| public E removeFirst() | 从此列表中删除并返回第一个元素 |
| public E removeLast() | 从此列表中删除并返回最后一个元素 |
Set
无序,不重复,无索引
其基本方法与collection接口类似:
| 方法名称 | 说明 |
| 把给定的对象添加到当前集合中(已存在返回false) |
| 清空集合中所有的元素 |
| 把给定的对象从当前集合中删除 |
| 判断当前集合中是否包含指定对象 |
| 判断当前集合是否为空 |
| 返回集合中元素的个数 / 集合的长度 |
这里介绍三种遍历方法:
- 迭代器
- 增强for循环
- lambda表达式
lambda:
ts.forEach(new Consumer<Integer>() {
@Override
public void accept(Integer integer) {
System.out.println(integer);
}
});
HashSet
无序,不重复,无索引
- 底层采用哈希表存储数据
- 哈希表是一种对于增删改查性能都比较好的结构
- jdk8开始采用数组+链表+红黑树(新增)组成
是哈希表的灵魂,哈希值是对象的整数表现形式,是对象通过哈希函数计算出的一个整数。
- 使用hashCode方法计算出来的int类型整数
- 这个方法定义在Object类中,所有对象都可调用,默认使用地址值计算
- 一般情况下会重写hashCode方法,使用对象内部属性值进行计算
按下Alt + Insert,可以让idea生成equals()和hashCode()方法
@Override
public boolean equals(Object o) {
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return age == student.age && Objects.equals(name, student.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
因为是数组+链表的方式,因此计算数组下标公式是: int index = (数组长度 - 1) & 哈希值;
如果index重复,先比较属性值(调用equals()方法判断,因此需要重写)如果相同就舍弃,不同就会将新元素用链表挂在老元素下面。
当数组快满时会扩容,当链表长度大于8且数组长度大于64会转成红黑树
因此如果集合中存储的是自定义对象,必须重写hashCode和equals方法
三个问题:
- 为什么HashSet遍历顺序和存入顺序不一样? :因为遍历是按照index顺序遍历的,存入位置是按照hash值计算出来的
- 为啥没索引:因为有链表存在,一个索引可能有多个数据,没必要
- 去重机制:相同属性的对象计算得到的index是相同的,再加上equals方法避免哈希碰撞。
LinkedHashSet
有序,不重复,无索引
继承自HashSet,每个元素又额外多了一个双链表机制记录存储顺序
要求去重且存取有序,才用LinkedHashSet
TreeSet
不重复,无索引,
- 可排序:默认从小到大排序,底层红黑树
排序原理: 对于数值类型,默认按照从小到大排序
对于字符,字符串类型,按照ASCLL码表中数字升序进行排序
两种方式
1.实现Comparable接口,重写抽象方法compareTo,默认是这种,因为排序规则内聚于类本身,是很多api以及Array.sort的默认排序规则
public class Student implements Comparable<Student> {
@Override
public int compareTo(Student o) { // o表示已经在红黑树存在的元素
return this.getAge() - o.getAge(); // 小的存左边
}
2.,创建TreeSet对象时,传递比较器Comparator指定规则
比如包装类String默认是按照字典序排序,那么如果想让短的在前,长的在后,一样长的比较字符,那么就需要传递比较器,因为包装类不是自定义类不能修改。方便快速,适合临时使用或临时更改排序规则
TreeSet<String> ts = new TreeSet<>(new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
int i = o1.length() - o2.length();
return i != 0 ? i : o1.compareTo(o2);
}
});
// 推荐使用Lambda 表达式
TreeSet<String> ts = new TreeSet<>((o1, o2) -> {
int i = o1.length() - o2.length();
return i != 0 ? i : o1.compareTo(o2);
});
Map
双列集合,键值对应,一个键值对java叫对象
常见API,顶层接口
| 方法名称 | 说明 |
| V put(K key, V value) | 添加元素,重复会覆盖,返回被覆盖的值 |
| V remove(objcet key) | 根据键删除元素, 返回删除的值 |
| void clear() | 移除所有元素 |
| boolean containsKey(Object key) | 判断集合是否包含指定键 |
| boolean containsValue(Object value) | 判断集合是否包含指定的值 |
| boolean isEmpty() | 判断集合是否为空 |
| int size() | 集合的长度,键值的对数 |
| Set<> keySet(); | 返回键集合 |
| V putIfAbsent(K, V); | 仅当键不存在才会插入,返回当前已存在的 value |
- 总是返回 ,不能直接转为 等具体类型(会抛 )。
- 而 可以安全返回 。底层使用优化的反射
- 键找值 keySet
Set<String> keys = map.keySet();
for(String a: map.keySet()){
String value = map.get(key);
System.out.println(key + "=" + value);
}
- 键值对遍历 entrySet();
先来介绍Entry:
// Entry是一个键值对对象,键值对对象有getKey()和getValue()方法
Map.Entry<String, String> entry;
for(Map.Entry<String, String> entry : mp.entrySet()){
System.out.println(entry.getKey() + ":" + entry.getValue());
}
- 先比较
- 再调用
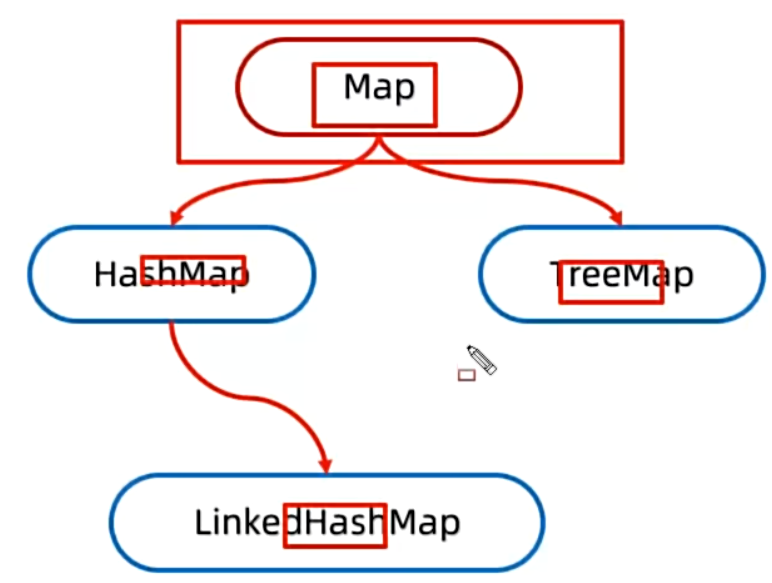
HashMap
1个 null 键和多个 null 值
基本方法和Map一致,基础实现类
特点都是由键决定的:无序,不重复,无索引
,都是哈希表结构,数组+链表+红黑树
LinkedHashMap
和LinkedList一样,有序,不重复,无索引
多一条双向链表记录存储顺序
TreeMap
底层同TreeSet,红黑树
由键决定特性,不重复,无索引,可排序。默认按照键的从小到大排序,也可自定义键的排序规则:
- 实现Comparable接口
- 创建集合时传递Comparator比较器对象,指定比较规则
- :Hashtable 是线程安全的。它的几乎所有公共方法(如 put, get, remove)都使用了 synchronized 关键字修饰。这意味着多个线程可以同时访问一个 Hashtable 实例而不会导致数据不一致。
- :Hashtable 的 。如果插入 null,会抛出 NullPointerException。
- :它继承自 Dictionary 类(这是一个过时的抽象类),并实现了 Map 接口。
- :它不保证键值对的遍历顺序,顺序可能会随时间变化。
- :由于它在整个方法上加了 synchronized 锁(即“对象锁”),在高并发环境下,所有线程必须竞争同一把锁,导致并发效率极低。
- :它是 JDK 1.0 的产物,其父类 Dictionary 已经过时。
- :它不支持红黑树优化,在极端哈希冲突下性能退化严重。
迭代器
在 Java 中,只要一个类实现了 ,它就可以使用 ,也就可以提供 。
而 ,所以它们天然支持迭代器。
ArrayList<Integer> list = new ArrayList<>();
Iterator<String> it = list.iterator();
while(it.hasNext()){
String str = it.next();
System.out.println(str);
}
注意,当需要在遍历时进行删除/增加/修改等操作,使用,不能用集合的方法
其实for(String s : list)就是采用了迭代器
还可用lambda表示
Stream流
好处是Stream 提供声明式、链式、惰性求值的数据处理方式,代码更简洁、可读性更强,并天然支持并行操作。
ArrayList<String> as = new ArrayList<>();
as.add("张雪放");
as.add("张三");
as.add("张三");
as.add("张五十");
as.stream().filter(s -> s.startsWith("张") && s.length() > 2).forEach(System.out::println);
Stream流类似工厂流水线,将目标集合的数据一条条的取出来并进行一系列中间方法后经由终结方法得到最终输出、
| 获取方式 | 方法名 | 说明 |
| 单列集合 | | Collection 中的默认方法 |
| 双列集合 | 无 | 无法直接使用 stream 流 |
| 数组 | | Arrays 工具类中的静态方法 |
| 一堆零散数据 | | Stream 接口中的静态方法 |
| 方法名称 | 描述 | 返回类型 |
| 过滤流中的元素,保留满足条件的元素 | |
| 对流中的每个元素执行给定的操作,并将结果映射到一个新的值 | |
| 类似于 map,但每个元素被映射到一个流,然后这些流会被合并成一个流 | |
| 去重操作,基于元素的 | |
| 自然排序(根据元素的 | |
| 根据提供的比较器进行排序 | |
| 对每个元素执行给定的操作,主要用于调试 | |
| 返回由该流的前 n 个元素组成的流 | |
| 跳过前 n 个元素,返回剩余元素组成的流 | |
| 合并两个流为一个流 | |
中间方法会返回新的Stream流,因此建议使用链式编程
| 方法名称 | 描述 | 返回类型 |
| 对流中的每个元素执行给定的动作 | |
| 将流中的元素收集到集合、列表、Map等数据结构中 | |
| 将流中的元素收集到一个数组中 | |
| 使用指定的归约操作对流中的元素进行累积计算 | |
| 根据提供的比较器找到最小元素 | |
| 根据提供的比较器找到最大元素 | |
| 计算流中元素的数量 | |
| 测试流中是否有至少一个元素匹配给定的谓词 | |
| 测试流中的所有元素是否都匹配给定的谓词 | |
| 测试流中是否没有元素匹配给定的谓词 | |
| 返回流的第一个元素,如果流为空则返回空的 Optional | |
| 返回当前流中的任意元素,如果流为空则返回空的 Optional。在并行流中,可能提高效率 | |
数组是 Java 最底层的数据结构之一,诞生于 Java 1.0,而 Stream API 是 Java 8 才加入的。 为了,不能给所有数组类型加方法(数组不是类,无法继承或扩展)。
所以,Java 团队在工具类 中提供了静态方法 来“桥接”数组和 Stream。
可变参数
要是计算N个数据的和?
没有可变参数前,getSum(int []arr)
在jdk5以后提出可变参数:方法形参个数可以变化
底层就是个数组
方法的形参中最多只能写一个可变参数,且只能写在参数最后面
格式:属性类型...名字:
public static void main(String[] args) {
getSum(1,2,3,4,5);
}
public static void getSum(int...args) {
int sum = 0;
for (int i : args) {
sum += i;
}
}
方法引用
将已有的方法当作函数式接口中的抽象方法的方法体
- 引用处必须是函数式接口
- 被引用方法必须已经存在
- 被引用方法的形参和返回值需要和抽象方法保持一致
- 被引用方法的功能需满足要求
类名::静态方法名
例: // 字符串转int
对象实例::成员方法
- 其他类: 其他类对象::方法名
- 本类: this::方法名
- 父类: super::方法名
为了创建对象,比如Student::new
list是一个字符串列表
Student[] su = list.stream().map(Student::new).toArray(Student[]::new);
利用Student类的构造函数创建对象
list.stream().map(String::toUpperCase).forEach(System.out::println);
// String::toUpperCase 看起来像类名引用,但它其实是一个“实例方法引用”,只不过 Java 允许用类名来引用该方法,前提是传入的对象就是该类的实例。
注意:
格式 数据类型[]::new
ArrayList<Integer> list = new ArrayList<>();
Collections.addAll(list, 1, 2, 3, 4);
Integer[] arr2 = list.stream().toArray(Integer[]::new);
面向对象
- 封装(Encapsulation):封装是将数据和方法组合在一起,对外部隐藏实现细节,只公开对外提供的接口。这样可以提高安全性、可靠性和灵活性。
- 继承(Inheritance):继承是从已有类中派生出新类,新类具有已有类的属性和方法,并且可以扩展或修改这些属性和方法。这样可以提高代码的复用性和可扩展性。
- 多态(Polymorphism):多态是指同一种操作作用于不同的对象,可以有不同的解释和实现。它可以通过接口或继承实现,可以提高代码的灵活性和可读性。
- 抽象(Abstraction):抽象是从具体的实例中提取共同的特征,形成抽象类或接口,以便于代码的复用和扩展。抽象类和接口可以让程序员专注于高层次的设计和业务逻辑,而不必关注底层的实现细节。
- 成员变量
- 成员方法
- 构造器
Java 构造器的主要作用是在创建对象时初始化该对象的状态,即为对象的成员变量赋予合 适的初始值,并执行必要的设置操作;它与类同名、没有返回类型,且在使用 关键字 创建对象时自动被调用,确保每个新创建的对象都处于一个有效、可用的初始状态。
- 代码块
- 内部类
修饰符讲解
| 修饰符 | 可修饰目标 | 核心特性 | 注意事项 | 好处 |
| 类、接口、方法、变量 | 完全公开:任何地方可访问。 | 一个文件中的顶级类必须是与文件名相同的那个才能被 | 提供最大灵活性,便于模块间调用和 API 暴露;支持跨包复用。 |
| 方法、变量(不能修饰顶级类) | 包内 + 所有子类可见(即使子类在不同包)。 | 比默认访问更宽;常用于父类设计供继承使用。 | 在封装性和继承性之间取得平衡,便于扩展而不完全暴露内部实现。 |
| default(无) | 类、方法、变量 | 包内可见(package-private)。 | 不写修饰符即默认;常被忽略但高频考。 | 限制访问范围到同一包,增强内聚性,适合包内协作而对外隐藏细节。 |
| 方法、变量、内部类 | 仅本类可见;最强封装。 | 外部无法直接访问;通过 getter/setter 控制。 | 最大程度保护数据安全和类的内部状态,提升代码健壮性和可维护性。 |
| 变量、方法、代码块、内部类 | 属于类,非实例;所有对象共享;无 | 静态方法不能访问非静态成员;工具类常用。 | 节省内存(无需实例)、便于工具方法/常量统一管理、启动时即可使用。 |
| 类、方法、变量 | 不可变: • 类 → 不能被继承 • 方法 → 不能被重写 • 变量 → 只能赋值一次 | | 增强安全性与稳定性,防止意外修改;利于编译器优化;明确设计意图。 |
| 类、方法 | 未实现: • 抽象类不能实例化 • 抽象方法无方法体,子类必须实现(除非也是抽象类) | | 支持模板方法模式,定义通用结构,强制子类实现特定行为,提高代码复用。 |
| 方法、代码块 | 线程同步:确保同一时间只有一个线程执行该段代码。 | 实例方法锁 | 保证多线程环境下的数据一致性,避免竞态条件和脏读。 |
| 变量 | 内存可见性 + 禁止指令重排序;不保证原子性。 | 常用于状态标志(如 | 轻量级线程通信机制,确保变量更新对所有线程立即可见,提升并发性能。 |
| 实例变量 | 不参与序列化;反序列化时为默认值(如 | 用于敏感字段(如密码)或临时数据。 | 保护隐私数据不被持久化,节省存储空间,避免序列化无关或临时状态。 |
顶级类 = 写在最外层的类,不在类的内部;
方法为什么是? → JVM 启动时还没有创建任何对象,必须通过类直接调用。静态方法能被重写吗? → 不能!子类定义同名静态方法是,不是多态。
工具类为何全用静态方法? → 无需创建对象,节省内存,调用简洁(如
)
内部类 的对象实例,和普通顶级类的对象,在堆内存中的结构完全一样;
继承

创建子类对象一定会创建父类对象,默认super父类的无参构造方法
继承的本质是子类对象使用父类对象的方法和变量(public)
- :Parent p = new Child(); —— 。用于统一处理不同子类(多态)。
- :Child c = (Child) p; —— 。用于恢复子类特有功能。
- :能转的前提:对象必须是你转的那个类型(或者是其子类)。兄弟类之间不能互转(Dog 不能转成 Cat)。
- :先用 instanceof 判断,再进行强制类型转换。
多态
多态是指:。只能调用父类中已有的方法(重写的会走子类版本),不能直接调用子类特有方法;它依赖继承、重写和向上转型,核心价值是——新增子类无需改动原有代码,是开闭原则的体现。
开闭原则(Open-Closed Principle,OCP)是面向对象设计的核心原则之一,由 Bertrand Meyer 提出,意思是:
- 变量调用:编译看左边,运行也看左边。
- 方法调用:编译看左边,运行看右边。
if (p instanceof Student) {
((Student) p).study(); // 安全转换
}
接口

*
- 定义的关键字不同。
- 子类继承或实现关键字不同。
- 类型扩展不同:抽象类是单继承,而接口是多继承。
- 方法访问控制符:抽象类中的抽象方法不能被 private 修饰;接口默认的是 public 控制符。
- 属性方法控制符:抽象类无限制,而接口有限制,接口默认的是 public 控制符。类型抽象类中的字段接口中的字段✅ 无限制:可用
、、、包私有❌ (即使不写)可以是普通变量(可变) (即常量) - 方法实现不同:抽象类中的普通方法必须有实现,抽象方法必须没有实现;而接口中普通方法不能有实现,但在 JDK 8 中的 static 和 defualt 方法必须有实现。
- 静态代码块的使用不同:抽象类可以有静态代码块,而接口不能有。
内部类
- 成员内部类
- 静态内部类
- 局部内部类
- 匿名内部类:掌握
成员内部类(Member Inner Class)
:属于外部类的实例,可访问外部类所有成员(包括 private)。
:必须先有外部类对象,才能创建内部类对象。
public class Outer {
private int x = 10;
class Inner {
void print() {
System.out.println(x); // 可直接访问外部类私有成员
}
}
public static void main(String[] args) {
Outer outer = new Outer();
Outer.Inner inner = outer.new Inner(); // 必须通过外部类实例创建
inner.print();
}
}
:
- 持有外部类引用,能访问其所有成员;
- 编译后生成 ;
- 不能定义 static 成员(除非是常量)。
static final部分常量是可以的,因为:对于 static final 修饰的基本类型或字符串,Java 编译器在编译阶段就会把它们替换为具体的数值,并且其存在于常量池访问它们不需要触发类的初始化逻辑,也不需要通过类引用
- 静态内部类(Static Nested Class)
:用 修饰,不依赖外部类实例,不能访问外部类非 static 成员。
:节省内存,线程安全,常用作工具类或辅助类。
public class Outer {
private static int y = 20;
private int x = 10;
static class StaticInner {
void print() {
System.out.println(y); // 可访问外部类 static 成员
// System.out.println(x); // ❌ 编译错误!不能访问非 static
}
}
public static void main(String[] args) {
Outer.StaticInner si = new Outer.StaticInner(); // 直接创建,无需外部实例
si.print();
}
}
✅ :
- 更像“顶级类”,只是命名空间在外部类内;
- 常用于 Builder 模式(如 );
- 无外部类引用,更轻量、安全。
- 局部内部类(Local Inner Class)
:定义在方法内部,作用域仅限于该方法。 :只能访问方法中 的局部变量。
public class Outer {
void method() {
int a = 100; // effectively final
class LocalInner {
void print() {
System.out.println(a); // ✅ 可访问
}
}
LocalInner li = new LocalInner();
li.print();
}
}
✅ :
- 很少用,多用于临时逻辑封装;
- 必须在定义它的方法内实例化;
- 访问局部变量需“事实 final”(Java 8+ 放宽了语法,但语义不变)。
- 匿名内部类(Anonymous Inner Class) ✅【重点掌握】
:没有名字,通常用于继承类或实现接口的。 :继承/实现 + 实例化一步完成。
虽然你没给它起名字,但 Java 是强类型语言,所有的对象必须属于某个类。当你写 new Runnable() { ... } 时,编译器在后台干了这些事:
- :它偷偷创建一个类,名字通常叫 外部类名$1。
- :让这个 $1 类去 implements Runnable。
- :你会发现文件夹里多了一个 Outer$1.class。
- :在代码运行到那一行时,new 出来的其实是这个 $1 类的对象。
所以,。
// 实现接口
Runnable r = new Runnable() { // 这里new的实际上是大括号的匿名内部类
@Override
public void run() {
System.out.println("匿名内部类");
}
};
// 继承类(如 Thread)
Thread t = new Thread() {
@Override
public void run() {
System.out.println("继承 Thread 的匿名类");
}
};
✅ :
- 广泛用于事件监听、回调、线程、Lambda 表达式前身;
- 编译后生成 、…;
- 同样只能访问 的局部变量;
- (仅限函数式接口)。
Object
Object是java中的顶级父类,所有的类都直接或间接的继承于Object类,其方法可以被所有类访问
成员方法:
| 方法名 | 说明 |
| public String toString() | 返回对象的字符串表示形式 |
| public boolean equals(Object obj) | 比较两个对象是否相等 |
| protected Object clone(int a) | 对象克隆,完全克隆所有属性值, |
| public static boolean isNull(Object a, Object b) | 判断是否为null |
| public static boolean nonNull(Object obj) | 判断对象是否为null |
这里的clone是保护方法,需要自己重写该方法调用super的clone,同时java提供了一个,继承了并重写方法表示该类可被克隆,这是标准写法:
public class Usr implements Cloneable{ ...
@Override
public Usr clone() {
try {
return (Usr) super.clone();
} catch (CloneNotSupportedException e) {
throw new AssertionError(e);
}
}
浅拷贝对引用类型只是复制指针,还是指向同一对象。深拷贝会创建新的引用对象。
为了使clone有深拷贝,对引用类型的属性单独操作就行了。
是 Java 中 Object 类提供的一个方法,用于在垃圾回收器准备释放对象所占用的内存空间之前调用。其定义如下:
protected void finalize() throws Throwable { }
finalize 方法的调用时机
与 C++ 的析构函数不同,Java 中的 finalize 方法并不能保证会被及时执行。垃圾回收的时机具有不确定性,可能在程序运行期间都未触发垃圾回收。
反射
反射允许对成员变量(包含内部类),成员方法和构造方法的信息进行编程访问。
例如,idea的代码提示就是利用的反射,将类里能调用的成员变量/方法进行展示,还能获取方法所有的形参

万物皆对象,获取以上四个对象分别是Class, Constructor, Field, Method
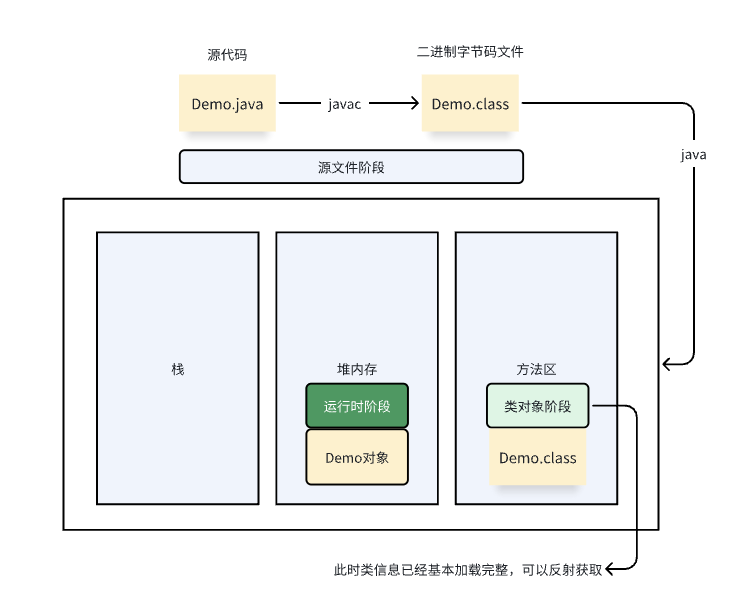
获取class
三种方式
- 该方法会触发指定类的加载、链接和初始化(包括执行 static 块),前提是该类尚未被加载或初始化。若类已存在,则直接返回其 对象。适用于需要动态加载并立即初始化类的场景(如 JDBC 驱动注册)。
- 类名在编译期已知。如果该类尚未加载,JVM 会触发加载和链接,但不会执行初始化(static 块不运行)。类信息会被放入方法区(或元空间), 对象可被获取,但实例尚未创建。适用于仅需类型引用而不触发初始化的场合(如泛型、注解处理)。
- 对象实例必须已经创建。这意味着该类早已完成加载、链接和初始化全过程。此方法返回的是对象实际运行时类型的 对象(支持多态),常用于反射中判断真实类型或动态调用。
获取构造方法
| 方法名 | 说明 |
| 返回该类所有的数组。仅包含可被当前类访问的 public 构造函数。 |
| 返回该类的数组,包括 private、protected、default 和 public 的,不考虑访问权限。 |
| 根据指定的参数类型,返回一个对象。如果找不到匹配的 public 构造方法,则抛出异常。 |
| 根据指定的参数类型,返回一个对象(包括 private)。若找不到则抛出异常。 |
| 使用此 |
| 设置是否取消 Java 访问检查。当 |
object.getModifiers();
返回int类型的权限修饰符信息,比如2代表private
获取成员变量
将Constructor改成Field
| 方法名 | 说明 |
| 为对象赋值 |
| 获取值 |
| 获取成员变量名字 |
| 获取成员变量类型 |
| 不仅对于private访问,用在static上还可以强制修改变量 |
- :Class.getDeclaredClasses() —— 获取类中定义的所有内部类(包括私有的)。
- :Class.getDeclaringClass() —— 如果当前类是内部类,返回它的外部类。
- :isMemberClass():是否是成员内部类。isLocalClass():是否是局部内部类。isAnonymousClass():是否是匿名内部类。
获取成员方法
方法签名:方法名+参数列表,java不允许方法签名重复
| 方法名 | 说明 |
| 返回该类及其所有父类中的数组,包括继承的方法。不包含 private、protected 或 default 方法。 |
| 返回该类的数组,包括 private、protected、default 和 public,但。 |
| 根据方法名和参数类型,返回一个。如果找不到匹配的 public 方法,则抛出 |
| 根据方法名和参数类型,返回一个(包括 private),但不包括继承的方法。若找不到则抛出异常。 |
| 调用该 |
反射的作用
- 获取一个类里的所有信息,然后执行业务逻辑
- 结合配置文件,动态的创建对象并调用方法
public static String informationToString(Object obj){
ClassInformation c = GetAllClassInformation.getInformation(obj);
return "类名:" + c.getClassname() + "\n" +
"构造器:" + Arrays.toString(c.getDeclaredConstructors()) + "\n" +
"属性:" + Arrays.toString(c.getDeclaredFields()) + "\n" +
"方法:" + Arrays.toString(c.getDeclaredMethods());
}
public static ClassInformation getInformation(Object obj){
Class<?> clazz = obj.getClass();
String classname = clazz.getName();
Constructor[] declaredConstructors = clazz.getDeclaredConstructors();
Field[] declaredFields = clazz.getDeclaredFields();
Method[] declaredMethods = clazz.getDeclaredMethods();
return new ClassInformation(classname, declaredConstructors, declaredFields, declaredMethods);
}
代理
:访问一个“代理对象”。由代理对象在调用目标方法前后,添加额外的逻辑(如:日志记录、事务控制、权限检查、性能监控等)。
代理如何知道类的方法/功能呢:通过实现同一个接口
是指在程序运行前,代理类的 .class 文件就已经存在了。
public class UserServiceProxy implements UserService {
private UserService target; // 引用真实对象
public UserServiceProxy(UserService target) {
this.target = target;
}
public void save() {
target.save(); // 调用真实业务
}
- 冗余:如果接口增加了方法,代理类也必须跟着改。
- 不灵活:一个代理类只能服务于一个特定的接口,如果项目中有 100 个 Service,就要写 100 个代理类。
是指代理类是在程序运行期间,通过反射机制动态生成的。
如何创建代理
类提供了为对象产生代理的核心方法:
public static Object newProxyInstance(ClassLoader loader, Class<?>[] interfaces, InvocationHandler h)
- :类加载器,用于加载动态生成的代理类。通常传入目标对象的类加载器。
- :接口数组,定义了代理对象应该实现哪些接口,也就是代理对象“长什么样”。
- :调用处理器,这是最核心的部分。当代理对象的方法被调用时,所有的调用都会被转发到这个处理器的invoke方法中。
例子:编写一个通用的代理工厂,它可以为创建一个性能监控代理,记录下每个方法的执行耗时。
public class ProxyFactory {
public static Object createPerformanceProxy(Object target) {
return Proxy.newProxyInstance(
target.getClass().getClassLoader(), // 使用目标对象类加载器
target.getClass().getInterfaces(), // 实现目标对象所实现的接口
(proxy, method, args) -> {
long startTime = System.currentTimeMillis();
// 核心操作:执行目标对象的原始方法
Object result = method.invoke(target, args);
long endTime = System.currentTimeMillis();
System.out.println(method.getName() + " 耗时: " + (endTime - startTime) + "ms");
return result;
}
);
}
}
现在可以为不同业务对象创建代理:
public class Main {
public static void main(String[] args) {
// 为 OrderService 创建代理
OrderService orderService = new OrderServiceImpl();
OrderService orderProxy = (OrderService) ProxyFactory.createPerformanceProxy(orderService);
orderProxy.createOrder("ORDER_20240521");
// 为 UserService 创建代理
IUserService userService = new UserServiceImpl();
IUserService userProxy = (IUserService) ProxyFactory.createPerformanceProxy(userService);
userProxy.addUser("Alice");
}
}
Proxy的缺陷
为什么 JDK 代理要求目标类?
- :JVM 生成的代理类名为 $Proxy0,它默认已经继承了 java.lang.reflect.Proxy。由于 Java 不支持多继承,它无法再继承你的目标类。
- :既然不能继承类,它只能通过实现相同的接口来“模仿”目标类的行为。
问题是,假设 Cat 类实现了 Animal 接口的 eat() 方法,但 Cat 自己还有一个特有的 run() 方法,那么代理类可以调用 eat(),但无法调用 run()
CGLIB
当目标类没有实现接口,或者我们需要调用类特有的方法时, 就派上用场了
CGLIB直接在内存中构建目标类的子类。
- :代理对象是目标类的“子类”。
- :天然拥有父类的所有的 public 方法(包括特有方法)。
在 Spring 框架中,若设置proxy-target-class=false,代理方式是自动切换的:
- 如果类实现了接口,Spring 默认使用 。
- 如果类没实现接口,Spring 强制切换为 。
在 Spring Boot 中,这个配置默认为 true。它的字面意思是:
- 开启后,Spring 即使发现你有接口,也会暴力使用 CGLIB 生成子类。
- :这样不仅能统计到接口方法,连类里的也能被 AOP 拦截并统计到(只要不是 final 方法)。
lambda
是 Java 8 引入的一种,用于表示(即没有名字的方法),主要用于简化(只有一个抽象方法的接口)的实现。
- :
- :只能用在上(如 、、 等)
- :避免写冗长的匿名内部类
Runnable r = () -> System.out.println("Hello, Lambda!");
r.run();
泛型
泛型是JDK5引入的特性,可以在约束操作的数据类型,并进行检查,因此将运行期的问题提前到了编译期间,避免了强制类型转换出现的异常
且java中的类型是伪泛型,在.class字节码文件时泛型会消失(泛型的擦除),都会被当作Object类型
当一个类中,某个变量的数据类型不确定时,就可以定义带有泛型的类
泛型不具备继承性,但是数据具备继承性
和 ,不能互相赋值
如何理解?
Java 的泛型在编译后会被类型擦除,变成原始类型,因此 和 在运行时其实是同一个类型,JVM 无法区分。为了防止类型安全问题(比如把 错误地放进 ),编译器不允许 继承自 ,即;但你放进泛型里的对象(如 )依然是 的子类,。
举例:
public class GenericsDemo5 {
public static void main(String[] args) {
// 创建集合对象
ArrayList<Ye> list1 = new ArrayList<>();
ArrayList<Fu> list2 = new ArrayList<>();
ArrayList<Zi> list3 = new ArrayList<>();
// 调用 method 方法
method(list1);
method(list2); // 报错
method(list3); // 报错
list1.add(new Ye());
list1.add(new Fu());
list1.add(new Zi());
}
public static void method(ArrayList<Ye> list) {
// ...
}
}
泛型的通配符:虽然不确定类型,但是希望只接收特定的类型,比如必须继承于某个父类
extends E:表示可以传递E或者E所有的子类类型
super E:表示可以传递E或者E所有的父类类型
public static void method(ArrayList<? extends E> list){
}
java 禁止创建泛型数组(如 ),是因为泛型在运行时会被擦除,而数组依赖运行时类型检查,若允许泛型数组,结合数组的协变性,会导致堆污染和隐式的 ,破坏类型安全。
// 假设这行能编译(实际上不能):
List<String>[] lists = new List<String>[2];
// 利用数组协变(List<String>[] 是 Object[] 的子类型)
Object[] objs = lists;
// 放一个 List<Integer> 进去 —— 编译器可能警告,但擦除后 JVM 无法阻止
objs[0] = new ArrayList<Integer>();
// 现在:lists[0] 实际上是一个 List<Integer>!
String s = lists[0].get(0); // ClassCastException!但代码看起来完全合法
协变
Cat 是 Animal 的子类(Cat ≤ Animal)
那么:
如果 List<Cat> 也是 List<Animal> 的子类型 → 协变
如果 List<Cat> 和 List<Animal> 没有子类型关系 → 不变
如果 List<Animal> 反而是 List<Cat> 的子类型 → 逆变(很少见)
处理异常
Java 中的所有异常类型都是Throwable类的子类。异常体系分为两大重要分支:
- Error:表示程序无法处理的严重问题
- Exception:表示程序许可处理的异常情况
Exception 又进一步分为:
- CheckedException(受检异常):编译器强制要求处理
- RuntimeException(运行时异常):编译器不强制处理
try catch很消耗性能,
try catch 注意点:
public class TryCatchExample {
public static void main(String[] args) {
try {
// 可能会抛出异常的代码
int result = 10 / 0; // 这里会抛出 ArithmeticException
System.out.println("结果是: " + result);
} catch (ArithmeticException e) {
// 捕获并处理特定异常
System.out.println("捕获到算术异常: " + e.getMessage());
} finally {
// 无论是否发生异常,都会执行
System.out.println("finally 块总是会被执行。");
}
}
}
如果try进行了return,那么在返回前会执行finally,如果finally还有return, 那么进行覆盖返回
是一种用于调试和测试的机制,用来验证程序中的“假设”是否成立。如果断言失败(即条件为 ),程序会抛出 ,通常表示代码中存在逻辑错误。
assert condition;
// 或
assert condition : message;
- :一个布尔表达式。如果为 ,则触发断言失败。
- (可选):当断言失败时,作为错误信息的一部分输出。
public class AssertionExample {
public static void main(String[] args) {
int age = -5;
// 简单断言
assert age >= 0 : "年龄不能为负数!";
System.out.println("年龄: " + age);
}
}
默认情况下,,所以即使 ,程序也不会报错。
要启用断言,必须在运行时加上 (enable assertions)参数:
javac AssertionExample.java
java -ea AssertionExample
输出(启用断言后):
Exception in thread "main" java.lang.AssertionError: 年龄不能为负数!
at AssertionExample.main(AssertionExample.java:6)
| 特性 | 断言(assert) | 异常(Exception) |
| 检查开发阶段的逻辑错误(内部假设) | 处理运行时可能出现的异常情况(如用户输入错误、IO 错误等) | |
| 不应被程序捕获或恢复(属于 bug) | 可被捕获并处理 | |
否(需 | 是 | |
| 通常关闭 | 必须保留 |
File
三种对象创建方式:
// 根据文件路径创建文件对象
// 根据父路径名字符串和子路径名字符串创建文件对象
// 根据父路径对应文件对象和子路径名字符串创建文件对象
| 方法名称 | 说明 |
| 判断此路径名表示的File是否为文件夹 |
| 判断此路径名表示的File是否为文件 |
| 判断此路径名表示的File是否存在 |
| 返回文件的大小(字节数量) |
| 返回文件的绝对路径 |
| 返回定义文件时使用的路径 |
| 返回文件的名称,带后缀 |
| 返回文件的最后修改时间(时间毫秒值) |
| 方法名称 | 说明 |
| 创建一个新的空的文件 |
| 创建单级文件夹 |
| 创建多级文件夹 |
| 删除文件、空文件夹 |
| 方法名称 | 说明 | 返回值类型 |
| 获取当前路径下所有文件和子目录的 | |
| 情况 | 返回结果 | 说明 |
| 路径不存在 | | 若文件夹路径无效或找不到,则返回 |
| 路径是普通文件(非目录) | | 只有目录才能调用 |
| 路径是空目录 | 长度为 0 的数组 | 即 |
| 路径是有内容的目录 | 包含所有文件和子目录的 | 每个元素都是一个 |
| 路径包含隐藏文件 | 返回数组中也包含隐藏文件 | 如 |
| 路径需要权限访问 | | 没有读取权限时无法列出内容 |
| 方法名称 | 说明 |
| 列出当前系统中所有可用的文件系统根目录(如 Windows 下的 C:、D:;Linux 下的 |
| 获取当前路径下所有文件和子目录的(不包含路径) |
| 使用 |
| 使用 |
| 使用 |
IO流
存取数据的方案,文件数据,网络数据等
- 作用:从外部源(如文件、网络)读取数据到程序中。关键词:读取(Read)
- 作用:将程序中的数据写入到外部目标(如文件、控制台)。关键词:写出(Write)
- 用于处理所有类型的文件(二进制文件),以字节(8位)为单位进行读写。适用文件类型:图片、音频、视频、可执行文件等。示例类:,
- 专门用于处理纯文本文件(如 , ),以字符(16位 Unicode)为单位进行读写。优点:自动处理编码转换(如 UTF-8、GBK)。示例类:,
💡 小贴士:
- 字节流适用于,包括非文本文件;
- 字符流仅适用于,效率更高且避免乱码,用记事本能打开
字节流
创建字节流输出对象
参数一:路径或File对象
参数二:续写开关,true表示追加
如何换行写:
win: \r\n ,编译器也会自动补全\n为\r\n
linux: \n
mac: \r
如果文件不存在会创建一个新的文件,但是要保证父级路径是存在的
String url = "src/main/java/mylearn/Multithreading/IoStream/test.txt";
try{
FileOutputStream fos = new FileOutputStream(url);
fos.write(97); // 这里写的是ASCII码a
fos.close();
}catch(Exception e){
e.printStackTrace();
}
- 一次写一个字节数据
- 一次写一个字节数组数据
- 写一个字节数组的部分数据,off是起始索引,len是写入长度
创建字节流输入对象
参数:路径或File对象(必须指向一个已存在的文件,否则会抛出 FileNotFoundException)
如何读取数据:
- 每次读取一个字节,返回该字节的 int 值(0~255),若返回 -1 表示已读到文件末尾
- 可配合循环逐字节读取,或使用字节数组批量读取以提高效率
String url = "src/main/java/mylearn/Multithreading/IoStream/test.txt";
try {
FileInputStream fis = new FileInputStream(url);
int data;
while ((data = fis.read()) != -1) {
System.out.print((char) data); // 将读取的字节转为字符输出
}
fis.close();
} catch (Exception e) {
e.printStackTrace();
}
- 一次读一个字节,返回读取的字节值(int 类型),到达末尾返回 -1
- 一次读取多个字节,存入字节数组 b 中,返回实际读取的字节数,到达末尾返回 -1
- 从输入流中最多读取 len 个字节,存入数组 b 的从 off 开始的位置,返回实际读取的字节数,到达末尾返回 -1
String url = "src/main/java/mylearn/Multithreading/IoStream/test.txt";
String url2 = "src/main/java/mylearn/Multithreading/IoStream/1.txt";
try (FileInputStream fis = new FileInputStream(url);
FileOutputStream fos = new FileOutputStream(url2)) {
byte[] buffer = new byte[1024];
int bytesRead;
while ((bytesRead = fis.read(buffer)) != -1) { // -1表示read结束了,而read会返回本次读取的长度
fos.write(buffer, 0, bytesRead); // 只写入实际读取的字节数
}
} catch (IOException e) {
e.printStackTrace();
}
字节缓冲流
将基本流包装成高级流,提高数据读写性能。以下两种方法底层自带了8192字节的缓冲区
| 方法名称 | 说明 |
| 把基本流包装成高级流,提高读取数据的性能 |
| 数据可能暂存于缓冲区中,需调用 |
传入的基本流对象会在缓冲流关闭时自动关闭
释放资源的方式
读取写入文件要求处理错误,jdk提供了方便的处理方式会自动释放资源
在 Java 中, ,适用于所有实现了 接口的 I/O 流对象(如 、 等)。
try (FileInputStream fis = new FileInputStream("input.txt");
FileOutputStream fos = new FileOutputStream("output.txt")) {
// 读写操作
int data;
while ((data = fis.read()) != -1) {
fos.write(data);
}
} catch (IOException e) {
e.printStackTrace();
}
// 流会自动关闭,无需手动调用 close()
- :无论是否发生异常, 和 都会在 结束时自动调用 。
- :用分号分隔即可。
- :避免了传统 块中手动关闭的繁琐和潜在错误。
💡 :只要使用 JDK 7 或更高版本, 来管理 I/O 资源。
字符集
ASCII
ASCII(American Standard Code for Information Interchange,美国信息互换标准代码)是一套基于拉丁字母的字符编码,共收录了 128 个字符,用一个字节就可以存储,它等同于国际标准 ISO/IEC 646。
ASCII 编码中第 0~31 个字符(开头的 32 个字符)以及第 127 个字符(最后一个字符)都是不可见的(无法显示),但是它们都具有一些特殊功能,所以称为控制字符( Control Character)或者功能码(Function Code)。无法表示中文字符
GBK
GBK(uo iao uozhan,国家标准扩展)是一种中文字符编码标准,主要用于简体中文的字符表示。它是对GB2312-80标准的扩展,包含了更多的汉字和符号,广泛应用于Windows系统、网页、数据库等中文信息处理环境中,使用两个字节(高位和低位)编码,高位最高位为1表示是双字节字符(比如中文)。
例:1xxxxxxx xxxxxxxx表示一个双字节字符,若单字节就是00000000 xxxxxxxx
Unicode
统一码(Unicode),又称万国码、国际码,是制定的国际标准,涵盖字符集及、、等编码方案。该标准通过为全球各语言字符分配唯一编码,解决传统编码的兼容性问题,支持跨语言、跨平台文本处理,其中UTF-8兼容并采用可变字节设计。
UTF-8 -16这种不是字符集,是unicode字符集的一种编码方式,UTF-8下中文占3字节

编码和解码
为何会有乱码?
- 编码和解码不统一
- 读取不完全,字节流单字节读取但编码是多字节
如何避免编码?
- 不要用字节流读取文本文件
- 编码解码时使用同一个码表,同一个编码方式
- :使用默认编码(不推荐):指定编码(推荐)推荐使用
- :使用默认编码(易乱码):指定编码(必须与编码时一致)推荐使用
字符流
字符流以 (char)为单位进行读写,底层自动处理编码转换,适合处理 。
核心类:(输入)、(输出)
创建字符输出流对象:
或
- :路径字符串或 对象
- :续写开关:追加写入(文件末尾) 或省略:覆盖写入(默认)
✅ 文件不存在时会自动创建(但父目录必须存在) ✅ 自动使用平台默认字符编码(如 UTF-8、GBK),(若需指定编码,应使用
)
- Java 中统一使用 ,运行时会根据操作系统自动转换:Windows → Linux/macOS →
- 也可手动写 获取当前系统换行符
String url = "src/main/java/mylearn/Multithreading/IoStream/test.txt";
try {
FileWriter fw = new FileWriter(url);
fw.write('a'); // 写一个字符
fw.write("你好\n"); // 写字符串并换行
fw.close();
} catch (Exception e) {
e.printStackTrace();
}
- 写一个字符(实际传入 char 的 int 值,如 或 )
- 一次写入整个字符数组
- 写入字符数组的一部分,从 开始,写 个字符
- 写入整个字符串(常用!)
- 写入字符串的一部分
是 的子类,默认使用系统编码。
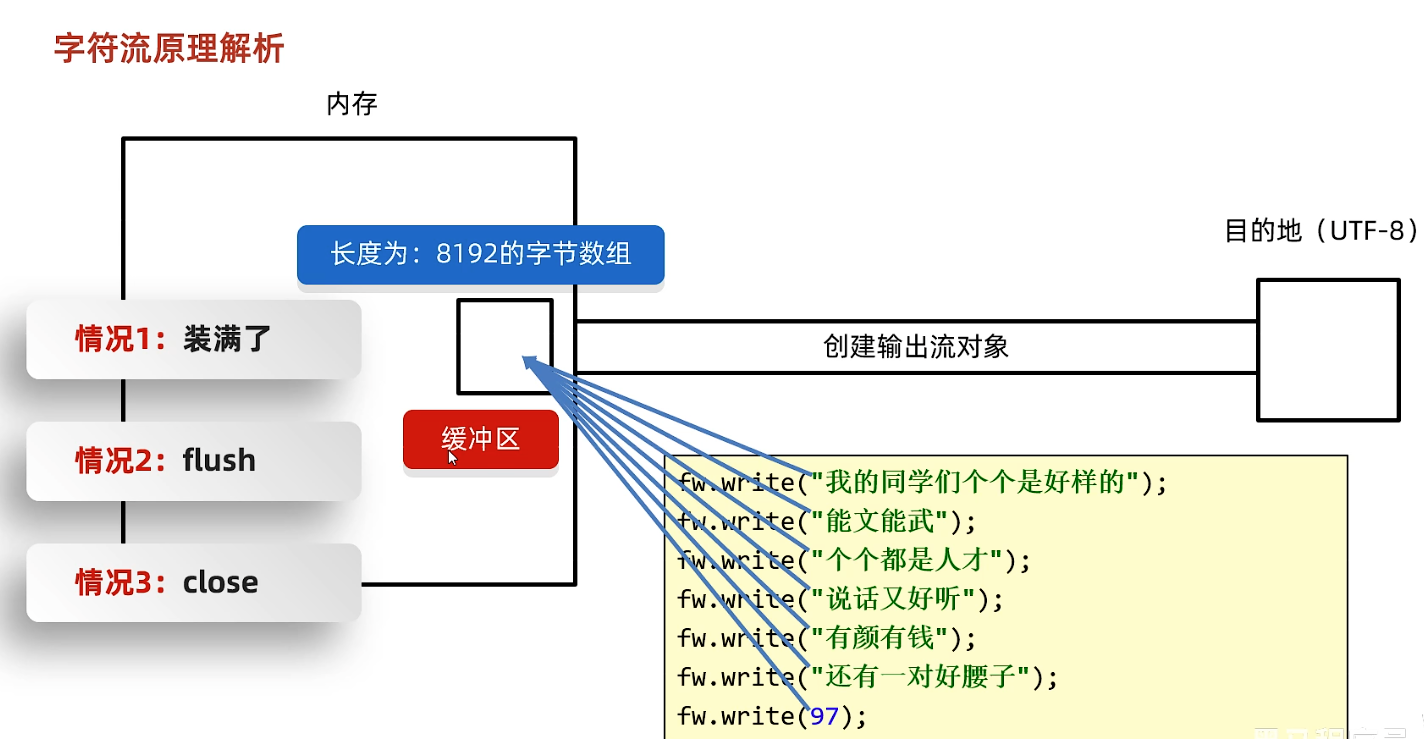
因此字符流写入会存在刷新问题
创建字符输入流对象:
- :路径或 对象
- :文件必须存在,否则抛出
- :使用平台默认字符编码(无法指定,若需控制编码请用 )
- 每次读一个字符,返回其 值(0~65535),返回 表示读到末尾
- 可逐字符读取,或使用字符数组批量读取(推荐,效率高)
String url = "src/main/java/mylearn/Multithreading/IoStream/test.txt";
try {
FileReader fr = new FileReader(url);
int ch;
while ((ch = fr.read()) != -1) {
System.out.print((char) ch); // 转为 char 输出
}
fr.close();
} catch (Exception e) {
e.printStackTrace();
}
- 读一个字符,返回其 int 值,末尾返回
- 将字符读入 数组,返回实际读取的字符数,末尾返回
- 最多读 个字符,存入 从 开始的位置,返回实际读取数
String src = "src/main/java/mylearn/Multithreading/IoStream/test.txt";
String dest = "src/main/java/mylearn/Multithreading/IoStream/1.txt";
try (FileReader fr = new FileReader(src);
FileWriter fw = new FileWriter(dest)) {
char[] buffer = new char[1024];
int charsRead;
while ((charsRead = fr.read(buffer)) != -1) {
fw.write(buffer, 0, charsRead);
}
} catch (IOException e) {
e.printStackTrace();
}
⚠️注意:
/ ,且。 若需指定编码(如 UTF-8),应使用:
InputStreamReader isr = new InputStreamReader(new FileInputStream(file), "UTF-8");
OutputStreamWriter osw = new OutputStreamWriter(new FileOutputStream(file), "UTF-8");
字节流没有缓冲区
读取:
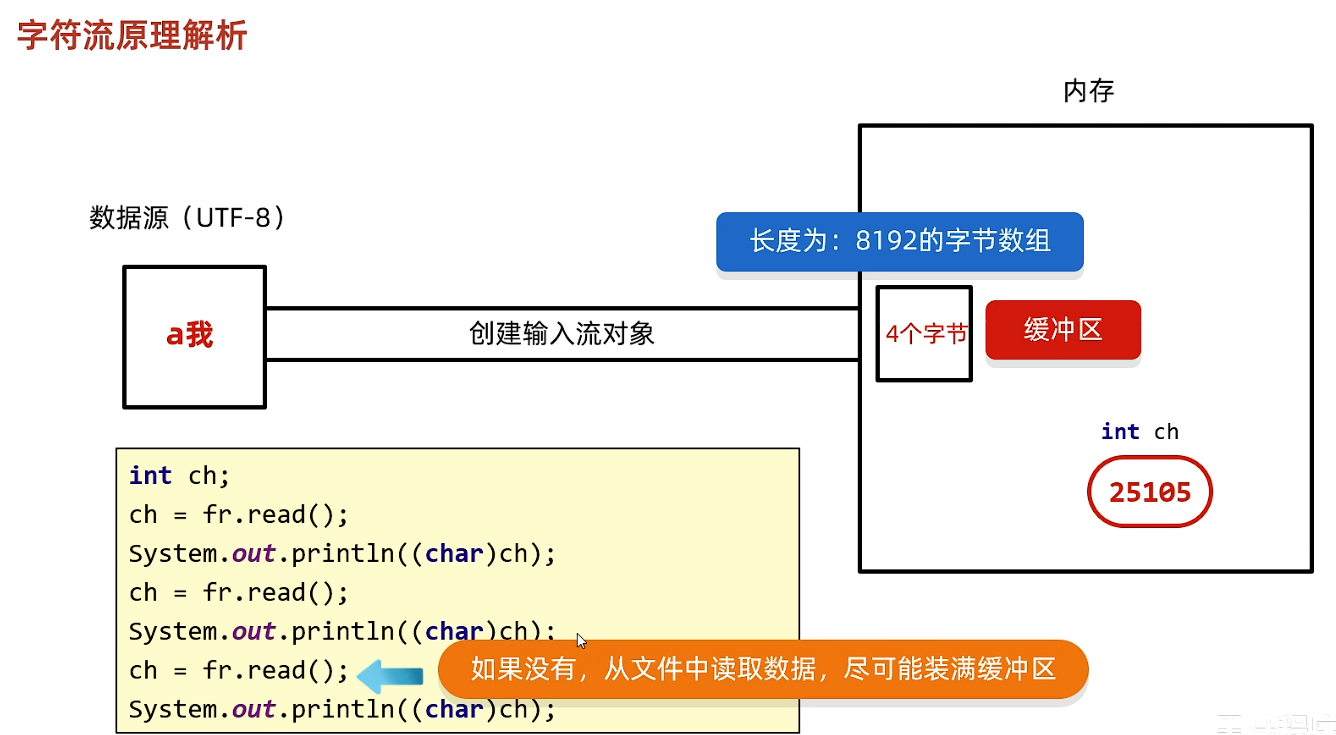
- 如果有 → 直接从缓冲区读取字符如果没有 → 调用底层字节流从文件中读取更多字节,填充缓冲区
- :通过底层 从文件中读取字节尽可能多地装满缓冲区(最多 8192 字节)如果文件已到末尾,则返回
- :从缓冲区中取出字节,并进行 (根据默认或指定编码)解码后得到字符,返回给上层程序空参的read方法:一次读取一个字节,遇到中文读多个,解码并转成十进制返回有参的read方法:把读取字节,解码,强转三步合并后放到数组中。
缓冲区刷新的方式是覆盖而不是重置0,
Java 的字符流(如
)在读取文本时,如果遇到多字节字符(比如 UTF-8 中文)被缓冲区分割的情况——例如缓冲区末尾只有前两个字节,第三个字节还在文件中——它会自动把不完整的字节暂存起来,等下一次读取新数据时,先拼接再解码,从而确保始终返回完整的正确字符,。这个过程对用户完全透明,无需手动处理。
字符缓冲流
| 方法名称 | 说明 | 特有方法 | 说明 |
| 把基本流包装成高级流,提高读取数据的性能 | readLine() | 读取一行数据,没有返回null |
| 数据可能暂存于缓冲区中,需调用 | newLine() | 跨平台的换行 |
缓冲区是16K ! 因为底层会创建一个8192大小的字符数组char
Randomse随机读取
创建随机访问对象 new RandomAccessFile(路径 或 File对象, 访问模式)
参数:
- :指向目标文件。
- (必须填),常用的有两种:"r":只读模式(若文件不存在会抛出 FileNotFoundException)。"rw":读写模式(若文件不存在,会自动帮你创建一个新文件)。
如何读取/写入数据:
- 它的内部自带一个(就相当于我们在Word里打字时的),默认在文件开头(索引为0)。
- 每次读或写数据后,这个指针会自动往后移动。
- :可以通过代码随意挪动这个“光标”的位置,实现“指哪读哪”、“指哪改哪”。
String url = "src/main/java/mylearn/Multithreading/IoStream/test.txt";
// 假设 text.txt 里面的内容是 "HelloWorld"
try {
// 使用只读模式 "r"
RandomAccessFile raf = new RandomAccessFile(url, "r");
// 把指针直接移动到第5个字节(跳过前面的"Hello")
raf.seek(5);
int data;
while ((data = raf.read()) != -1) {
System.out.print((char) data); // 会输出 "World"
}
raf.close();
} catch (Exception e) {
e.printStackTrace();
}
| 核心方法 | 读写方式与功能描述 |
| 将文件指针(光标)绝对定位到文件中的指定位置 |
| 获取位置:返回当前文件指针(光标)所在的字节偏移量。 |
| 读取数据:与普通字节流一致,一次读取一个字节或填充字节数组;读取完成后,指针自动向后移动。 |
| 写入数据:写入字节数组。配合 |
String url = "src/main/java/mylearn/Multithreading/IoStream/raf_demo.txt";
// 使用读写模式 "rw" (推荐配合 try-with-resources 自动关流)
try (RandomAccessFile raf = new RandomAccessFile(url, "rw")) {
// 1. 先写入一段基础数据
raf.write("Hello Java".getBytes());
// 此时光标在末尾(位置10)
// 2. 需求:我们想单独读取前面的 "Hello"
raf.seek(0); // 把光标挪回文件开头
byte[] buffer = new byte[5];
raf.read(buffer); // 读取5个字节
System.out.println("读取的内容: " + new String(buffer)); // 输出: Hello
// 3. 需求:把 "Java" 改成 "Code"
raf.seek(6); // 把光标挪到 'J' 的位置 (索引为6)
raf.write("Code".getBytes()); // 写入后,文件内容变成了 "Hello Code"
// 4. 查看当前光标位置
System.out.println("当前光标位置: " + raf.getFilePointer()); // 输出: 10
} catch (IOException e) {
e.printStackTrace();
}
实际应用中通常使用,它打破传统字节流的性能瓶颈,直接对接操作系统底层机制,专攻海量数据与高并发场景。
- 传统流是一个字节或一个数组地搬运,而 FileChannel 必须配合 ByteBuffer(缓冲区)使用。它直接在内存中分配一块连续空间批量读写,减少了程序与磁盘交互的次数。
- 传统文件上传:磁盘 -> 操作系统内核 -> JVM内存 -> 操作系统网络层 -> 网卡(来回拷贝4次)。 FileChannel (transferTo / transferFrom 方法):可以直接让操作系统把数据从磁盘丢给网卡,,极大节省 CPU 性能和内存开销。
- 支持将一个几十GB的大文件,直接“映射”到操作系统的物理内存中。,操作系统会自动在后台帮你同步到硬盘,是处理超大文件的“终极杀器”。
转换流
转换流( 和 )的作用是在: 将字节输入流按指定字符编码解码为字符,供字符流读取; 将字符按指定编码编码为字节,写入字节输出流。它们使得程序能以字符(文本)方式安全、正确地处理文本数据,同时兼容底层只接受字节的 I/O 设备,并通过显式指定编码(如 UTF-8)避免乱码问题。
| 流类型 | 类名 |
| |
|
// 参数1: 字节输入流(如 FileInputStream)
// 参数2: 字符编码(推荐显式指定,避免乱码)
InputStreamReader isr = new InputStreamReader(
new FileInputStream("input.txt"),
"UTF-8"
);
// 参数1: 字节输出流(如 FileOutputStream)
// 参数2: 字符编码(必须与读取时一致)
OutputStreamWriter osw = new OutputStreamWriter(
new FileOutputStream("output.txt"),
"UTF-8"
);
序列化流
序列化流(如 和 )的作用是将 Java 对象转换为字节序列并保存到本地文件(序列化),之后可以从文件中读取字节并重新在内存中还原出原对象(反序列化)序列化的主要目的是
实现:Serializable 接口: 要使一个类可序列化,需要让该类实现 java.io.Serializable 接口,这告诉 Java 编译器这个类可以被序列化,例如:
import java.io.Serializable;
public class MyClass implements Serializable {
// 类的成员和方法
}
使用 ObjectOutputStream 类来将对象序列化为字节流,以下是一个简单的实例:
MyClass obj = new MyClass();
try {
// 创建文件输出流,指向名为 "object.ser" 的文件,用于将字节写入磁盘
FileOutputStream fileOut = new FileOutputStream("object.ser");
// 将 FileOutputStream 包装为 ObjectOutputStream,使其具备写入 Java 对象的能力
ObjectOutputStream out = new ObjectOutputStream(fileOut);
// 将 obj 对象序列化(转换为字节流)并写入到 "object.ser" 文件中
out.writeObject(obj);
out.close();
fileOut.close();
} catch (IOException e) {
e.printStackTrace();
}
使用 ObjectInputStream 类来从字节流中反序列化对象,以下是一个简单的实例:
MyClass obj = null;
try {
// 创建文件输入流,从名为 "object.ser" 的文件中读取字节数据
FileInputStream fileIn = new FileInputStream("object.ser");
// 将 FileInputStream 包装为 ObjectInputStream,使其具备从字节流中还原 Java 对象的能力
ObjectInputStream in = new ObjectInputStream(fileIn);
// 从输入流中读取对象(反序列化),并强制转换为 MyClass 类型,赋值给 obj
// 注意:readObject() 返回的是 Object 类型,必须显式向下转型
obj = (MyClass) in.readObject();
in.close();
fileIn.close();
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
比如新增了属性,若没有指定版本号,那么会报错读取的序列化对象版本号和指定类型版本号不匹配,指定版本号就不会在新增内容时重新计算版本号,可以在Idea设置自动生成

若想让某个成员变量的值不参与序列化过程,那么可以加关键字修饰,标记的成员变量不参与序列化过程
读写多个对象
比如向文件追加写入多个对象,那么读取时如果循环读取,文件读空后会报 EOFException异常,但我们不能用异常来判断是否读空。所以一般规定,这样直接读一次集合就行了。
一定先写再读
打印流
只能写(输出),不能读
打印流是Java IO体系中用于,它提供了一系列重载的和方法,可以方便地输出各种数据类型。Java提供了两种打印流:
- :字节打印流,处理字节数据
- :字符打印流,处理字符数据
- 自动刷新:可以在输出换行符或字节数组后自动刷新缓冲区
- 不抛出IOException:打印流的方法不会抛出IOException,而是设置一个内部错误标志
- 格式化输出:提供了格式化输出的方法,如printf()
- 支持多种数据类型:可以直接打印各种基本数据类型和对象,实现数据的原样写出
- 特有的写出方法可以实现自动刷新和换行
- 控制台输出:System.out和System.err就是PrintStream实例
- 日志记录:将程序运行信息输出到日志文件
- 数据导出:将数据以格式化的方式输出到文件或网络
- 调试信息输出:在开发过程中输出调试信息
PrintStream
| 构造方法 | 说明 |
| 关联字节输出流/文件/文件路径 |
| 指定字符编码 |
| 自动刷新 |
| 指定字符编码且自动刷新 |
字节流底层没有缓冲区,因此自动刷新开不开都一样
| 成员方法 | 说明 |
| 常规方法:规则跟之前一样,将指定的字节写出 |
| 特有方法:打印任意数据,自动刷新,自动换行 |
| 特有方法:打印任意数据,不换行 |
| 特有方法:带有占位符的打印语句,不换行 |
PrintWriter
| 构造方法签名 | 参数说明 | 功能描述 |
| | 不自动刷新、使用默认字符编码 |
| | 若 |
| | |
| | 创建一个写入文件的 |
| | 通过文件名和指定编码(Java 11+ 支持)。 |
| 成员方法 | 说明 |
| 常规方法:规则跟之前一样,将指定的字符写出 |
| 特有方法:打印任意数据,自动刷新,自动换行 |
| 特有方法:打印任意数据,不换行 |
| 特有方法:带有占位符的打印语句,不换行 |
解压缩流
java默认只识别zip格式
位于InputStream下的拓展类,用于解压缩
创建解压缩流并遍历ZipEntry对象:
ZipInputStream zip = new ZipInputStream(new FileInputStream(src));
private static boolean unzip(File zipFile, String destDir) throws IOException {
// 判断destDir是否存在
File destFile = new File(destDir);
if (!destFile.exists()) {
destFile.mkdirs();
}
// 创建解压缩流
ZipInputStream zis = new ZipInputStream(new FileInputStream(zipFile));
ZipEntry entry;
while((entry = zis.getNextEntry()) != null){
System.out.println("扫描到:" + entry.getName());
if(entry.isDirectory()){
System.out.println("创建目录:" + destDir + entry.getName());
File file = new File(destDir + entry.getName());
file.mkdirs();
}else{
// 创建输出流写出
FileOutputStream fos = new FileOutputStream(new File(destDir, entry.toString()));
byte[] b = new byte[8192]; // 增大缓冲区提高效率
int bytesRead;
while((bytesRead = zis.read(b)) != -1){
fos.write(b, 0, bytesRead); // 只写入实际读取的字节数
}
System.out.println("解压缩文件:" + destDir + entry.getName() + " 成功");
fos.close();
// 表处理完一个文件条目后,需要调用closeEntry()方法来结束当前条目的读取操作,释放相关资源,然后才能继续读取下一个条目
zis.closeEntry();
}
}
zis.close();
return true;
}
解压缩流的方法命名都很形象,见名知意,另外,可能会解压缩出如desktop.ini(文件夹个性化信息), thumbs.db(缩略图信息),因为这些是win自带的压缩工具悄悄创建的,用户不可见但是java解压缩流会看到并处理,可以跳过
压缩流
位于OutputStream下的拓展类,用于压缩, 压缩本质就是把每一个文件/文件夹看成ZipEntry对象放到压缩包中
import java.io.*;
import java.nio.file.Files;
import java.util.zip.ZipEntry;
import java.util.zip.ZipOutputStream;
/**
* 将指定源文件或目录压缩为 ZIP 文件
*
* @param srcFile 要压缩的源文件或目录
* @param zipFile 目标 ZIP 文件
* @return 是否成功
* @throws IOException
*/
private static boolean zip(File srcFile, File zipFile) throws IOException {
// 确保目标 ZIP 文件的父目录存在
File parentDir = zipFile.getParentFile();
if (parentDir != null && !parentDir.exists()) {
parentDir.mkdirs();
}
try (FileOutputStream fos = new FileOutputStream(zipFile);
ZipOutputStream zos = new ZipOutputStream(fos)) {
if (srcFile.isDirectory()) {
// 压缩整个目录
addFolderToZip("", srcFile, zos);
} else {
// 压缩单个文件
addFileToZip("", srcFile, zos);
}
System.out.println("压缩完成: " + zipFile.getAbsolutePath());
return true;
}
}
/**
* 将单个文件添加到 ZIP 流中
*/
private static void addFileToZip(String basePath, File file, ZipOutputStream zos) throws IOException {
String entryName = basePath + file.getName();
System.out.println("添加文件: " + entryName);
// 创建 ZIP 条目
ZipEntry entry = new ZipEntry(entryName);
zos.putNextEntry(entry);
try (FileInputStream fis = new FileInputStream(file)) {
byte[] buffer = new byte[8192];
int bytesRead;
while ((bytesRead = fis.read(buffer)) != -1) {
zos.write(buffer, 0, bytesRead);
}
}
zos.closeEntry(); // 结束当前条目
}
/**
* 递归将整个文件夹添加到 ZIP 流中
*/
private static void addFolderToZip(String basePath, File folder, ZipOutputStream zos) throws IOException {
File[] files = folder.listFiles();
if (files == null) return;
for (File file : files) {
String entryPath = basePath + folder.getName() + "/";
if (file.isDirectory()) {
// 递归处理子目录
addFolderToZip(entryPath, file, zos);
} else {
// 添加文件
addFileToZip(entryPath, file, zos);
}
}
}
工具类
这里着重使用国产新工具类工具包
一个Java基础工具类,对文件、流、加密解密、转码、正则、线程、XML等JDK方法进行封装,组成各种Util工具类,同时提供以下组件:
| 模块 | 介绍 |
| hutool-aop | JDK动态代理封装,提供非IOC下的切面支持 |
| hutool-bloomFilter | 布隆过滤,提供一些Hash算法的布隆过滤 |
| hutool-cache | 简单缓存实现 |
| hutool-core | 核心,包括Bean操作、日期、各种Util等 |
| hutool-cron | 定时任务模块,提供类Crontab表达式的定时任务 |
| hutool-crypto | 加密解密模块,提供对称、非对称和摘要算法封装 |
| hutool-db | JDBC封装后的数据操作,基于ActiveRecord思想 |
| hutool-dfa | 基于DFA模型的多关键字查找 |
| hutool-extra | 扩展模块,对第三方封装(模板引擎、邮件、Servlet、二维码、Emoji、FTP、分词等) |
| hutool-http | 基于HttpUrlConnection的Http客户端封装 |
| hutool-log | 自动识别日志实现的日志门面 |
| hutool-script | 脚本执行封装,例如Javascript |
| hutool-setting | 功能更强大的Setting配置文件和Properties封装 |
| hutool-system | 系统参数调用封装(JVM信息等) |
| hutool-json | JSON实现 |
| hutool-captcha | 图片验证码实现 |
| hutool-poi | 针对POI中Excel和Word的封装 |
| hutool-socket | 基于Java的NIO和AIO的Socket封装 |
| hutool-jwt | JSON Web Token (JWT)封装实现 |
| hutool-ai | AI大模型封装 |
多线程
是操作系统进行资源分配和调度的基本单位,是一个正在运行的程序的实例。 是 CPU 调度和执行的最小单位,被包含在进程中,是进程中的实际执行单元。 同一进程内的多个线程,但每个线程拥有。
- :CPU 逻辑核心数决定了能的线程上限(如 8 核 CPU 真正并行跑 8 个线程)。
- :依靠 CPU 毫秒级的“时间片轮转”,让单核也能制造出多线程“同时运行”的假象。
| 通俗说法 | 操作系统术语 | Java | 含义说明 | 典型触发方式 | 是否可恢复 |
| 新建 | New | | 线程对象已创建,但尚未启动 | | ✅(调用 |
| 就绪 | Ready | | 线程已启动,等待 CPU 调度(具备运行条件) | 调用 | —(属于运行态) |
| 运行 | Running | | 线程正在 CPU 上执行代码 | 获得 CPU 时间片后自动进入 | — |
| 阻塞 | Blocked | | 线程等待获取 (该锁被其他线程持有) | 进入 | ✅(锁释放后) |
| 等待 | Waiting | | 线程,直到被其他线程显式唤醒 | | ✅(需被唤醒) |
| 睡眠 /计时等待 | Timed Waiting | | 线程,超时后自动恢复 | | ✅(超时或中断) |
| 死亡 | Terminated / Dead | | 线程执行完毕(正常结束或抛出未捕获异常) | | ❌(不可重启) |
操作系统分配任务的时间是毫秒级,用户交互高的线程有高优先级
为什么 Java 要把 Ready 和 Running 合并为 RUNNABLE? 因为现代操作系统(时间片轮转)切换线程的速度太快了(毫秒甚至微秒级),在 JVM 层面去细分这两个状态没有实际指导意义,干脆统称为“可以运行的状态”。
实现方式
1.将类声明为Thread的子类,重写run方法,接下来可以分配并启动该子类的实例
// 1. 定义线程类
class MyThread extends Thread {
@Override
public void run() {
System.out.println("Hello from thread!");
}
}
// 2. 启动线程(通常放在 main 方法中)
public class Main {
public static void main(String[] args) {
MyThread t1 = new MyThread();
t1.setName("线程1");
MyThread t2 = new MyThread();
t2.setName("线程2");
t1.start(); // 进程已经就绪,等待操作系统调用
t2.start();
}
}
线程1Hello from thread!
线程2Hello from thread!
2.实现Runnable接口
// 区别在于真正运行的是线程对象,需要创建线程对象
MyRun mr = new MyRun(); // 实现了接口并重写了run方法的对象
// 创建线程对象
Thread t1 = new Thread(mr);
t1.start(); // 开启线程
以上创建线程的前两种传统方式( 和 )默认不支持直接返回结果。
3.
import java.util.concurrent.Callable;
public class MyCallable implements Callable<Integer> {
@Override
public Integer call() throws Exception {
int sum = 0;
for (int i = 1; i <= 100; i++) {
sum += i;
}
return sum; // 返回计算结果
}
}
import java.util.concurrent.FutureTask;
public class ThreadDemo {
public static void main(String[] args) throws Exception {
// 1. 创建一个实现了 Callable 接口的对象(任务)
MyCallable mc = new MyCallable();
// 2. 创建 FutureTask 对象(用于管理线程执行结果)
FutureTask<Integer> ft = new FutureTask<>(mc);
// 3. 创建 Thread 对象,并将 FutureTask 传入
Thread t1 = new Thread(ft);
// 4. 启动线程
t1.start();
// 5. 获取线程执行的结果(阻塞等待)
Integer result = ft.get(); // 等待任务完成并返回结果
System.out.println("1~100 的和是:" + result); // 输出:5050
}
}
Thread常见成员方法
| 方法名称 | 说明 |
| 返回当前线程的名称。 |
| 设置线程的名字。也可以在构造方法中设置(如 |
| 获取当前正在执行的线程对象(静态方法)。常用于获取调用线程信息。也就是线程本身 |
| 让当前线程休眠指定时间(单位:),释放CPU资源。抛出 |
| 设置线程的优先级(1~10,默认为5)。数值越大优先级越高,但不保证调度顺序。 |
| 获取线程的优先级。 |
| 将线程设置为守护线程( |
| 提示调度器让出CPU给其他线程(非阻塞),但不保证会切换(因为下次调度还会参与竞争) |
| 等待当前线程执行完毕后再继续执行后续代码(插入/插队作用)。可重载为 |
:当 JVM 中所有的 非守护线程\都结束时,JVM 会立即退出,此时所有守护线程会被强制终止,无论它们是否执行完毕。比如t1线程从1打印到10,守护线程t2从1打印到100,那么t1结束后,t2可能只打印到30就结束了
例子:比如开一个窗口传输文件,那么就可以把传输文件设置成守护线程,窗口关闭了自动不传输了
public static void main(String[] args) {
int flag = 0;
Thread t1 = new Thread(() -> {
flag = 1; // 编译错误,flag是main线程内变量,其他线程可见但是不可修改(final)
});
Thread t2 = new Thread(() -> {
System.out.println(flag);
});
t1.start();
t2.start(); // 进入就绪态
t1.join();
}
join() 的作用是:让当前线程(通常是主线程)等待指定的线程执行完毕后再继续执行。
也就是main这个线程会在t1.join()这里阻塞等待,但是t2其执行是不受影响的
锁
比如一个进程中的变量i被两个线程同时修改,可能会被覆盖而丢失数据
变量存储在主内存中,CPU 通过高速缓存(Cache)加速访问;当多个线程并发修改同一变量时,各自可能将变量加载到自己核心的缓存中进行计算。由于缓存与主存之间存在,若没有同步机制(如
或),一个线程对变量的修改可能尚未写回主存,另一个线程就从主存或自己的缓存中读取了旧值,导致。当它们先后将结果写回时,就会发生——例如两个线程同时执行,都读到,各自加 1 后写回,最终结果丢失了一次更新。这种问题并非因为缓存“销毁”数据,而是,使得多线程在无协调的情况下操作共享状态,造成竞态条件(Race Condition)。因此,必须通过 Java 的内存模型同步机制,强制刷新缓存、保证操作的原子性和可见性,才能避免数据被错误覆盖。
同步代码块
同步代码块是多线程编程中用于解决数据安全问题的重要机制。它通过关键字限制多个线程对共享资源的同时访问,确保在同一时刻只有一个线程可以执行同步代码块,从而避免数据不一致或损坏的情况。
synchronized(锁){
操作共享数据的代码
}
其实还有public synchronized void method(),非静态锁this, 静态锁当前类的.class,一般不推荐使用因为粒度不可调节(锁对象不能自己指定),会锁住方法里的所有代码
对象锁和类锁
我们需要通过一个标识来表示这个锁有没有被人持有,被哪个持有了
在java中是借助于对象头表示的
- 对象头
- 实例数据
- 对齐填充Java 要求对象大小是 8 字节的整数倍,并通过“对齐填充”实现这一要求,主要目的是提升 CPU 内存访问效率、简化垃圾回收,并保证跨平台一致性。
[ 栈(Stack) ]
└─ 局部变量 a ────┐
│ (引用/指针)
▼
[ 堆(Heap) ]
└─ Student 对象实例
├─ **对象头(Object Header)**
│ ├─ **Mark Word** ← 存储锁状态(无锁、偏向锁、轻量级锁、重量级锁)、GC 分代年龄、hashCode 等
│ └─ **Klass Pointer** → 指向方法区中的 Student.class
│
└─ 实例数据(Instance Data)
├─ name: String
└─ age: int
[ 方法区(Method Area / Metaspace) ]
└─ Student.class
├─ 方法字节码(如 getName(), setName())
├─ 字段描述(name: String, age: int)
├─ 静态变量(static fields) ← 若有 synchronized(static method),锁的是该类的 Class 对象
└─ 运行时常量池
---------------------------
[ 堆中的 Student 对象 ]
┌───────────────────────┐
│ Object Header │
│ ├─ Mark Word │ ← 存储锁状态、GC 信息、hashCode 等
│ └─ Klass Pointer │ ← 指向方法区中的 Student.class 元数据的指针
├───────────────────────┤
│ Instance Data │
│ ├─ name: "Alice" │
│ └─ age: 20 │
└───────────────────────┘
如何加锁
上面讲了同步代码块里需要加个锁,然后锁又分为对象锁和类锁以及锁在哪,以下是如何加锁
- : 或 用于保护,粒度是每个线程实例
- :用于保护,粒度是类(每个类可以有多个线程)
- JDK5以后提供Lock锁对象,实现类实例化
死锁
死锁的必要条件:
- :资源在同一时刻只能被一个进程占用。如果资源可以被多个进程共享,则不会发生死锁。例如,打印机在被一个进程使用时,其他进程无法同时使用该打印机。
- :一个进程在持有至少一个资源的同时,又请求其他被占用的资源。如果进程在请求资源时不持有任何资源,或者可以释放已持有的资源,则不会发生死锁。
- :已经获得的资源在未使用完之前,不能被其他进程强行剥夺。只有占用资源的进程主动释放资源,其他进程才能使用。如果系统允许强制剥夺资源,则不会发生死锁。
- :多个进程之间形成一种头尾相接的循环等待资源关系。如果线程之间没有形成循环等待,则不会发生死锁。例如,进程A等待进程B的资源,进程B等待进程C的资源,而进程C又等待进程A的资源,这样就形成了一个循环等待的局面。
等待唤醒机制*
多线程协作,下面以生产者消费者为列
| 方法名称 | 说明 | 注意事项 |
| 当前线程释放锁,并进入等待状态,直到被其他线程调用 | 必须在 |
| 随机唤醒一个正在等待的线程(处于 | 只能唤醒一个线程,可能不是期望的线程, 只有当所有等待线程时,才能安全使用 |
| 唤醒所有正在等待的线程(处于 | 更安全,推荐用于复杂共享资源场景。存在‘惊群’风险。 |
的是: 。
在 Java 中,每个对象都有一个与之关联的 和 。
当你在一个对象上调用:
synchronized (obj) {
obj.wait();
}
该线程会:
- 释放 的锁;
- 进入 的 ,进入阻塞状态。
而在同一个对象 上调用:
synchronized (obj) {
obj.notifyAll();
}
那么:
,并尝试重新竞争
的锁。
例:
class Buffer {
private final int MAX_SIZE = 10;
private Object[] items = new Object[MAX_SIZE];
private int count = 0;
private int in = 0;
private int out = 0;
public synchronized void produce(Object item) throws InterruptedException {
while (count == MAX_SIZE) {
wait(); // 缓冲区满,生产者等待
}
items[in] = item;
in = (in + 1) % MAX_SIZE;
count++;
notifyAll(); // 唤醒所有等待的消费者
}
public synchronized Object consume() throws InterruptedException {
while (count == 0) {
wait(); // 缓冲区空,消费者等待
}
Object item = items[out];
out = (out + 1) % MAX_SIZE;
count--;
notifyAll(); // 唤醒所有等待的生产者
return item;
}
}
阻塞队列
| 对比项 | ArrayBlockingQueue | LinkedBlockingQueue |
| 有界数组(循环队列) | 链表(节点) | |
| 必须指定, | 默认无界(最大 | |
| 是(构造时可选) | 否 | |
| 单锁(入队/出队共用) | 双锁(入队、出队分离) | |
| 一般 | 通常更高(尤其高并发) | |
| 小(固定数组) | 较大(每个元素额外 Node 对象) | |
| 固定缓冲区、内存敏感 | 高吞吐、不确定数据量 |
两者均线程安全、不支持
元素,且实现 接口。
| 方法 | 功能 | 阻塞行为 |
| 入队,队满时等待 | 是(永久阻塞) |
| 出队,队空时等待 | 是(永久阻塞) |
| 尝试入队,失败返回 | 否 |
| 尝试出队,失败返回 | 否 |
| 带超时入队 | 是(最多等 timeout) |
| 带超时出队 | 是(最多等 timeout) |
| 入队,失败抛异常 | 否 |
| 查看队首(不移除) | 否 |
线程池
提交任务时,线程池会创建新的线程对象,任务完毕后线程回归线程池不会死亡,线程池满后新提交的任务会阻塞等待。
| 方法名称 | 说明 |
| 创建一个没有上限的线程池 |
| 创建有上限的线程池 |
常用方法
| 方法签名 | 说明 |
| 提交一个无返回值的任务( |
| 提交一个有返回值的任务( |
| 提交一个 |
| 立即尝试停止所有正在执行的任务,暂停等待任务,并返回等待执行的任务列表。 |
| 平滑关闭线程池:不再接受新任务,但会继续执行已提交的任务。 |
| 判断线程池是否已调用 |
| 判断线程池是否已完全终止(所有任务都已完成)。 |
| 阻塞当前线程,直到线程池终止或超时,常配合 |
💡 :
- 只能用于 ,无返回值;
- 支持 和 ,可获取执行结果或异常;
- 关闭线程池时,推荐先调用 ,再用 等待结束,以实现优雅关闭。
自定义线程池
这里引入核心线程,临时线程,阻塞队伍长度三个概念:
- 线程池创建新的线程对象,任务完毕后线程回归线程池不会死亡
- 线程池满后(核心线程占满)新来的任务进入阻塞队伍
- 核心线程占满且阻塞队伍长度也达到最大值时,创建临时线程用于处理后续到来的任务
举个例子,核心线程池最大三个,阻塞队伍长三,临时线程两个,那么如果来了八个线程,前三个占用核心线程,后三个进入阻塞队伍等待核心线程,最后两个才开启临时线程处理。
.
- 线程池和队列都满时,直接抛出 。适合不能容忍任务丢失、需立即感知失败的场景。
- 静默丢弃新提交的任务,不抛异常。不推荐使用,因为无法知道任务被丢弃。
- 丢弃队列中等待时间最长的任务,然后尝试重新提交当前任务。适合新任务比旧任务更重要的场景(如实时数据处理)。
- 由提交任务的线程(调用者)自己执行该任务。能避免任务丢失,但会阻塞调用线程,降低系统吞吐量。适合希望“降级但不丢任务”的场景。
ThreadPoolExecutor pool = new ThreadPoolExecutor(
3, // 参数一:核心线程数量(corePoolSize)—— 不能小于0
6, // 参数二:最大线程数量(maximumPoolSize)—— 必须 >= 核心线程数
60L, // 参数三:空闲线程最大存活时间(keepAliveTime)—— 单位由 timeUnit 决定
TimeUnit.SECONDS, // 参数四:时间单位(timeUnit)—— 使用 TimeUnit 指定
new LinkedBlockingQueue<>(10), // 参数五:任务队列(workQueue)—— 不能为 null,此处使用有界队列
Executors.defaultThreadFactory(), // 参数六:创建线程工厂(threadFactory)—— 不能为 null
new ThreadPoolExecutor.CallerRunsPolicy() // 参数七:任务拒绝策略(handler)—— 不能为 null
);
// 提交多个任务测试线程池行为
for (int i = 0; i < 20; i++) {
final int taskId = i;
pool.submit(() -> {
System.out.println("任务 " + taskId + " 正在执行,线程:" + Thread.currentThread().getName());
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
});
}
// 关闭线程池
pool.shutdown();
try {
if (!pool.awaitTermination(5, TimeUnit.SECONDS)) {
pool.shutdownNow(); // 强制关闭
}
} catch (InterruptedException e) {
pool.shutdownNow();
Thread.currentThread().interrupt();
}
最大并行数
事宜的线程池大小需要计算得出。
首先,操作系统可能并不会将所有的逻辑处理器分给java虚拟机,可通过以下代码查看:
int count = Runtime.getRuntime().availableProcessors();
System.out.println(count);
- : ,比如count = 8,那么设置为9 (防止偶尔一个线程出问题)
- :
cpu计算时间,等待时间需要工具类测试
网络编程
- C/S:Client/Server 客户端/服务器架构
- B/S:Browser/Server 浏览器/服务器架构
区别:B/S架构无需下载,但是资源不能过大,依赖网络传输资源
C/S架构需要下载本地资源,网络仅传输必要内容,可以将质量做的很好,但开发安装部署更新麻烦
学习计算机网络时我们一般采用折中的办法,也就是中和 OSI 和 TCP/IP 的优点,采用一种只有五层协议的体系结构,这样既简洁又能将概念阐述清楚。
- :设备在网络中的地址,是唯一标识
- :应用程序在设备中唯一的标识
- :数据在网络中传输的规则,常见的协议有UDP,TCP,http,https,ftp
InetAddress
此类表示互联网协议(IP)地址对象
获取类:
InetAddress address = InetAddress.getByName(机器名称/IP地址)
获取IP地址的主机名
address.getHostName();
返回文本显示中的IP地址字符串
address.getHostAddress(); // 比如192.168.1.100
端口号
应用程序在设备中的唯一标识
由两个字节表示的整数,取值范围0 ~ 65535
其中0~1023之间的端口用于一些知名的网络服务或应用
1024以上可以自己使用,一个端口号只能被一个应用程序使用
协议
计算机网络中,连接和通信的规则被称为网络通信协议
- 用户数据报协议
- 面向无连接的协议,不管是否连接成功没收到就算了
- 速度快,有大小限制一次最多64K,数据不安全
- 传输控制协议
- 面向连接的,三次握手,四次挥手,丢包检查等
- 速度慢,没有大小限制,数据安全
UDP通信程序
DatagramSocket ds = new DatagramSocket();
// 会绑定一个端口,空参即随机选一个可用的,也可以指定端口如7788
- :构造一个用于发送的数据报包。
- ::要发送的数据字节数组(内容)。:要发送的数据长度(≤ )。:目标主机的 IP 地址( 对象)。:目标主机的端口号(0~65535)。
示例
// 创建发送端,端口为7788
DatagramSocket ds = new DatagramSocket(7788);
// 打包数据
String data = "hello UDP";
byte[] bys = data.getBytes();
// 目标主机是本地localhost
InetAddress address = InetAddress.getLocalHost();
// 目标可用端口
int port = 9999;
DatagramPacket dp = new DatagramPacket(bys, bys.length, address, port);
ds.send(dp);
// 释放资源
ds.close();
绑定的端口和上文目标主机端口号一致
// 创建接收端
DatagramSocket ds = new DatagramSocket(9999);
// 创建接收端数据包
byte[] bys = new byte[1024];
DatagramPacket dp = new DatagramPacket(bys, bys.length);
// 接收
ds.receive(dp);
// 解析数据包
byte[] data = dp.getData();
int len = dp.getLength();
InetAddress address = dp.getAddress();
int port = dp.getPort();
System.out.println("接收到数据:" + new String(data,0,len));
System.out.println("来自:" + address.getHostAddress() + ":" + port);
// 释放资源
ds.close();
UDP三种通信方式
在 TCP/IP 网络中,。 比如:
- 普通单播地址(如 ) → 路由器会尝试把它送到那台特定主机。
- 广播地址() → 路由器/交换机会把它发给。
- 组播地址() → 路由器会根据“谁加入了这个组”来决定是否转发和复制。
所以,,告诉网络:“请按某种特殊方式处理这个包”。
(Unicast):一对一,上文的就是单播
(Multicast):创建一个组,只有加入该组的主机接收,发送端不用显式加入组
IP 地址分为 A、B、C、D、E 类:
- A/B/C:用于单播
- E 类:实验用
- 这是 IANA(互联网号码分配机构)规定的。。
发送MulticastSocket:指定组播地址,如224.0.0.1这一组然后加入
// 创建发送组
MulticastSocket mu = new MulticastSocket(7788);
// 目标主机是本地组
InetAddress address = InetAddress.getByName("224.0.0.1");
// 加入组
mu.joinGroup(address);
其他不变
接收同理监听的地址就是224.0.0.1这一组,即可加入组
(Broadcast):发送的数据会被接收。它。这是为了防止“广播风暴”——如果全世界都能收到你的广播,网络就瘫痪了。
为啥用255.255.255.255就能广播?
- 在二进制中,,全 1。
- 当网络设备(如交换机、网卡)看到目标 IP 是 ,就会,而是。
- 同时,交换机会把这个帧 到所有端口(除了接收端口),确保局域网内每台机器都收到。
TCP通信程序
发送端
// 创建Socket对象并连接服务端
Socket socket = new Socket("127.0.0.1", 7878);
// 写出数据
String str = "hello,tcp";
socket.getOutputStream().write(str.getBytes());
// 写出结束标记
socket.shutdownOutput();
// 接收回写数据
InputStream is = socket.getInputStream();
InputStreamReader isr = new InputStreamReader(is);
int b;
while((b = isr.read()) != -1){
System.out.print((char)b);
}
isr.close();
socket.close();
接收端
// 创建接收端对象
ServerSocket ss = new ServerSocket(7878);
// 等待客户端连接
Socket socket = ss.accept();
// 获取输入流
InputStream is = socket.getInputStream();
InputStreamReader isr = new InputStreamReader(is);
int b;
while ((b = isr.read()) != -1) {
System.out.print((char) b);
}
// 回写数据
String str = "ok TCP";
socket.getOutputStream().write(str.getBytes());
socket.close();
ss.close();
TCP发送文件线程池版
package mylearn.Multithreading.webcoding;
import java.io.*;
import java.net.ServerSocket;
import java.net.Socket;
import java.util.concurrent.*;
public class TCPPoolRead {
public static void main(String[] args) throws IOException {
// 创建线程池:core=3, max=5, queue=2
ThreadPoolExecutor pool = new ThreadPoolExecutor(
3,
5,
60L,
TimeUnit.SECONDS,
new ArrayBlockingQueue<>(2),
Executors.defaultThreadFactory(),
new CustomRejectedHandler() // ← 使用自定义拒绝策略
);
ServerSocket serverSocket = new ServerSocket(7878);
System.out.println("服务器启动,监听端口 7878...");
try {
while (true) {
Socket clientSocket = serverSocket.accept();
System.out.println("新连接来自: " + clientSocket.getRemoteSocketAddress());
pool.execute(new ClientHandler(clientSocket));
}
} finally {
serverSocket.close();
pool.shutdown();
}
}
// 每个客户端连接的处理任务
static class ClientHandler implements Runnable {
private final Socket socket;
public ClientHandler(Socket socket) {
this.socket = socket;
}
// 提供 getter 供拒绝策略访问 socket
public Socket getSocket() {
return socket;
}
@Override
public void run() {
try {
// 假设客户端发送的是文件内容(这里简化为文本)
InputStream input = socket.getInputStream();
FileOutputStream fileOut = new FileOutputStream("received_file_" + System.currentTimeMillis());
byte[] buffer = new byte[1024];
int len;
while ((len = input.read(buffer)) != -1) {
fileOut.write(buffer, 0, len);
}
fileOut.close();
// 回写成功消息
Thread.sleep(50000);
OutputStream output = socket.getOutputStream();
output.write("文件上传成功!\n".getBytes());
output.flush(); // 刷新缓冲区
} catch (IOException e) {
System.err.println("处理客户端时出错: " + e.getMessage());
} catch (InterruptedException e) {
throw new RuntimeException(e);
} finally {
try {
socket.close();
} catch (IOException e) {
// ignore
}
}
}
}
// 自定义拒绝策略:关闭被拒绝的连接
static class CustomRejectedHandler implements RejectedExecutionHandler {
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
System.out.println("线程池已满,正在处理被拒绝的连接...");
if (r instanceof ClientHandler) {
Socket socket = ((ClientHandler) r).getSocket();
System.out.println("线程池已满,拒绝连接: " + socket.getRemoteSocketAddress());
try {
// 发送错误信息给客户端
OutputStream out = socket.getOutputStream();
out.write("服务器繁忙,请稍后再试。\n".getBytes());
out.flush();
} catch (IOException e) {
// 写入失败
System.err.println("发送错误信息给客户端时出错: " + e.getMessage());
} finally {
try {
socket.close(); // 关闭 socket,释放内核缓冲区和连接资源
} catch (IOException e) {
// 捕获错误
System.err.println("关闭 socket 时出错: " + e.getMessage());
}
}
} else {
// 如果不是 ClientHandler,按默认方式处理
}
}
}
}
package mylearn.Multithreading.webcoding;
import java.io.*;
import java.net.Socket;
public class TestClient {
public static void main(String[] args) {
int totalClients = 20; // 创建 20 个客户端连接
for (int i = 0; i < totalClients; i++) {
final int clientId = i + 1;
new Thread(() -> {
Socket socket = null;
try {
System.out.println("客户端 " + clientId + " 尝试连接...");
socket = new Socket("127.0.0.1", 7878);
// 发送少量数据(模拟文件上传)
OutputStream out = socket.getOutputStream();
out.write(("Client-" + clientId + ": Hello from client!\n").getBytes());
socket.shutdownOutput(); // 告诉服务端“我发完了”
// 读取服务端响应
InputStream in = socket.getInputStream();
BufferedReader reader = new BufferedReader(new InputStreamReader(in));
String response = reader.readLine(); // 因为服务端只写一行
if (response != null) {
System.out.println("客户端 " + clientId + " 收到: " + response);
} else {
System.out.println("客户端 " + clientId + " 未收到响应(连接可能被关闭)");
}
} catch (Exception e) {
System.err.println("客户端 " + clientId + " 出错: " + e.getMessage());
} finally {
if (socket != null) {
try {
socket.close();
} catch (IOException ignored) {}
}
}
}).start();
// 可选:稍微错开连接时间,避免瞬间冲击(也可以去掉)
try {
Thread.sleep(10);
} catch (InterruptedException ignored) {}
}
// 主线程等待一段时间,让所有客户端完成
try {
Thread.sleep(10000);
} catch (InterruptedException ignored) {}
}
}
日志
一般不用java自带的,使用框架提供的,比如springboot的SLF4J + Logback